Classificador baseline de regressão logística
Nas últimas 2 aulas, você viu como a seleção de atributos é valiosa em entrevistas de Machine Learning. Outro conjunto de perguntas comuns trata de engenharia de atributos e de como ela ajuda a melhorar o desempenho do modelo.
Neste exercício, você vai criar um novo atributo no conjunto de dados loan_data do Capítulo 1, comparar a acurácia de modelos de Regressão Logística no conjunto antes e depois da engenharia de atributos, comparando os rótulos de teste com os valores previstos da variável alvo Loan Status.
Todos os pacotes relevantes já foram importados para você: matplotlib.pyplot como plt, seaborn como sns, LogisticRegression de sklearn.linear_model, train_test_split de sklearn.model_selection e accuracy_score de sklearn.metrics.
A engenharia de atributos é considerada uma etapa de pré-processamento antes da modelagem:
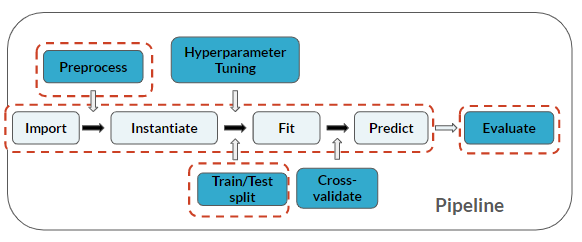
Este exercício faz parte do curso
Praticando perguntas de entrevista de Machine Learning em Python
Exercício interativo prático
Experimente este exercício completando este código de exemplo.
# Create X matrix and y array
X = loan_data.____("____", axis=1)
y = loan_data["____"]
# Train/test split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=123)
# Instantiate
logistic = ____()
# Fit
logistic.____(____, ____)
# Predict and print accuracy
print(____(y_true=____, y_pred=logistic.____(____)))