Distribuições de treino/teste
Em uma entrevista de Machine Learning, você certamente vai trabalhar com dados de treino e de teste. Como discutido antes, um desempenho ruim do modelo pode ocorrer se as distribuições dos conjuntos de treino e teste forem diferentes.
Neste exercício, você usará funções de sklearn.model_selection, além de seaborn e matplotlib.pyplot, para dividir loan_data em um conjunto de treino e um conjunto de teste e visualizar suas distribuições para identificar possíveis discrepâncias.
Observe que seaborn e matplotlib.pyplot já foram importados no seu ambiente com os aliases sns e plt, respectivamente.
O pipeline agora inclui o Train/Test split:
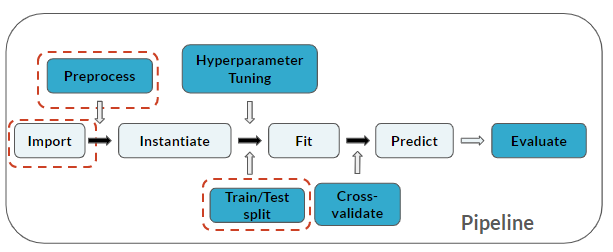
Este exercicio faz parte do curso
Praticando perguntas de entrevista de Machine Learning em Python
Instruções do exercicio
- Faça um subconjunto de
loan_datacontendo apenas as variáveisCredit ScoreeAnnual Income, e a variável alvoLoan Status— nessa ordem. - Crie uma divisão 80/20 de
loan_datae atribua-a aloan_data_subset. - Crie pairplots de
trainingSetetestSet(nessa ordem), definindo o argumentohuecomo a variável alvoLoan Status.
exercicio interativo prático
Tente este exercicio completando este código de exemplo.
# Create `loan_data` subset: loan_data_subset
loan_data_subset = ____[['____','____','____']]
# Create train and test sets
trainingSet, testSet = ____(____, ____=___, random_state=123)
# Examine pairplots
plt.figure()
sns.____(____, hue='____', palette='RdBu')
plt.show()
plt.figure()
sns.____(____, hue='____', palette='RdBu')
plt.show()