Árvore de decisão
Nos três capítulos anteriores, você aprendeu várias técnicas que ajudam a abordar muitos aspectos de uma entrevista de Machine Learning. Neste capítulo, você conhecerá diferentes maneiras de garantir que qualquer modelo que pedirem para você criar ou discutir em uma entrevista de Machine Learning seja generalizável, corretamente avaliado e bem escolhido entre outras opções possíveis.
Neste exercício, você vai se aprofundar no ajuste de hiperparâmetros de uma árvore de decisão no conjunto de dados loan_data.
Aqui, você vai ajustar min_samples_split, que é o número mínimo de amostras necessárias para criar uma divisão binária adicional, e max_depth, que é a profundidade máxima da árvore. Quanto mais profunda a árvore, mais divisões ela tem e, portanto, mais informações sobre os dados ela captura.
A matriz de atributos X e o rótulo-alvo y já foram importados para você.
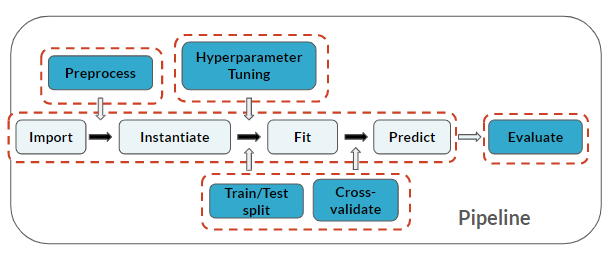
Observe que você está novamente realizando todas as etapas do pipeline de Machine Learning!
Este exercicio faz parte do curso
Praticando perguntas de entrevista de Machine Learning em Python
exercicio interativo prático
Tente este exercicio completando este código de exemplo.
# Import modules
from sklearn.tree import ____
from sklearn.metrics import accuracy_score
# Train/test split
X_train, X_test, y_train, y_test = train_test_split(____, ____, test_size=0.30, random_state=123)
# Instantiate, Fit, Predict
loans_clf = ____()
loans_clf.____(____, ____)
y_pred = loans_clf.____(____)
# Evaluation metric
print("Decision Tree Accuracy: {}".format(____(____,____)))