Metoda sylwetkowa
W poprzedniej lekcji miałeś okazję zobaczyć, jak różna liczba skupień wpływa na działanie algorytmu K-średnich. W kontekście rozmowy kwalifikacyjnej jest to szczególnie istotne – optymalna liczba skupień daje najlepsze wyniki.
W tym ćwiczeniu użyjesz funkcji silhouette_score() z biblioteki sklearn.metrics na algorytmach K-średnich uruchomionych na zbiorze danych diabetes, aby zastosować metodę sylwetkową do wyznaczenia optymalnej liczby skupień. Podczas obliczania wyniku zostanie użyta odległość euklidesowa, co zapewnia porównywalność z metodą łokcia.
Macierz cech X, której użyjesz do trenowania modeli K-średnich, została już przygotowana.
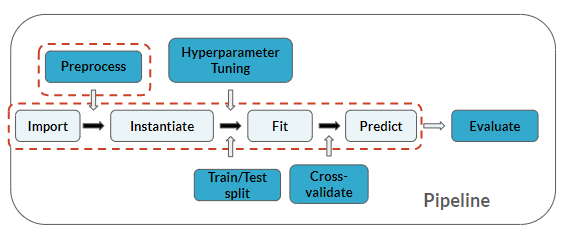
Znajdujesz się w tym samym miejscu w potoku co w poprzednich ćwiczeniach, ale tym razem dodasz również etap predykcji:
To ćwiczenie jest częścią kursu
Ćwiczenie pytań rekrutacyjnych z uczenia maszynowego w Pythonie
Interaktywne ćwiczenie praktyczne
Spróbuj tego ćwiczenia, uzupełniając ten przykładowy kod.
# Import modules
from sklearn.____ import ____
from sklearn.____ import ____