Metody filtrowania i owijania
Pytania dotyczące redukcji wymiarowości zbioru danych są bardzo częste podczas rozmów kwalifikacyjnych z uczenia maszynowego. Jednym ze sposobów na ograniczenie wymiarowości jest wybranie tylko istotnych cech ze zbioru danych.
W tym ćwiczeniu przećwiczysz metodę filtrowania na ramce danych diabetes, a następnie dwa różne rodzaje metod owijania z walidacją krzyżową. Do wizualizacji korelacji, przetwarzania danych i zastosowania technik selekcji cech użyjesz bibliotek pandas, matplotlib.pyplot i seaborn.
Macierz cech z usuniętą kolumną zmiennej docelowej (progression) jest załadowana jako X, natomiast zmienna docelowa – jako y.
Zwróć uwagę, że biblioteki pandas, matplotlib.pyplot i seaborn zostały już zaimportowane do przestrzeni roboczej odpowiednio jako pd, plt i sns.
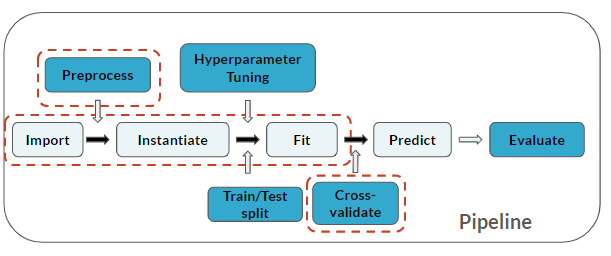
Do potoku przetwarzania dodano krok Walidacja krzyżowa (który dotyczy ostatnich 3 kroków):
To ćwiczenie jest częścią kursu
Ćwiczenie pytań rekrutacyjnych z uczenia maszynowego w Pythonie
Interaktywne ćwiczenie praktyczne
Spróbuj tego ćwiczenia, uzupełniając ten przykładowy kod.
# Create correlation matrix and print it
cor = ____.____()
print(____)
# Correlation matrix heatmap
plt.figure()
sns.____(____, annot=True, cmap=plt.cm.Reds)
plt.show()
# Correlation with output variable
cor_target = abs(cor["progression"])
# Selecting highly correlated features
best_features = ____[____ > ____]
print(____)