Bazowy klasyfikator regresji logistycznej
W ostatnich 2 lekcjach poznałeś wartość selekcji cech w kontekście rozmów kwalifikacyjnych z uczenia maszynowego. Kolejny zestaw typowych pytań, których możesz się spodziewać, dotyczy inżynierii cech i tego, jak wpływa ona na poprawę wydajności modelu.
W tym ćwiczeniu przeprowadzisz inżynierię nowej cechy na zbiorze danych loan_data z Rozdziału 1, porównasz dokładność modeli regresji logistycznej na zbiorze danych przed inżynierią cech i po niej, zestawiając etykiety testowe z wartościami przewidywanymi dla zmiennej docelowej Loan Status.
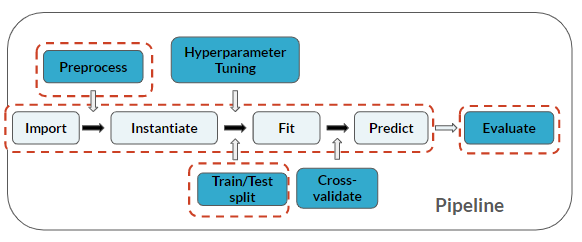
Wszystkie niezbędne pakiety zostały już zaimportowane: matplotlib.pyplot jako plt, seaborn jako sns, LogisticRegression z sklearn.linear_model, train_test_split z sklearn.model_selection oraz accuracy_score z sklearn.metrics.
Inżynieria cech jest etapem wstępnego przetwarzania danych przed modelowaniem:
To ćwiczenie jest częścią kursu
Ćwiczenie pytań rekrutacyjnych z uczenia maszynowego w Pythonie
Interaktywne ćwiczenie praktyczne
Spróbuj tego ćwiczenia, uzupełniając ten przykładowy kod.
# Create X matrix and y array
X = loan_data.____("____", axis=1)
y = loan_data["____"]
# Train/test split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=123)
# Instantiate
logistic = ____()
# Fit
logistic.____(____, ____)
# Predict and print accuracy
print(____(y_true=____, y_pred=logistic.____(____)))