Creare insiemi di test casuali
Prima di costruire un modello di concessione prestiti più sofisticato, è importante tenere da parte una porzione dei dati sui prestiti per simulare quanto bene il modello preverrà gli esiti dei futuri richiedenti.
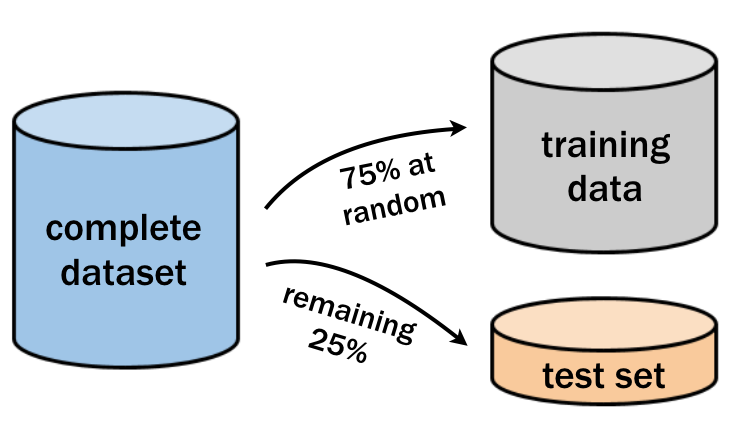
Come mostrato nell'immagine seguente, puoi usare il 75% delle osservazioni per l'addestramento e il 25% per il test del modello.
La funzione sample() può essere usata per generare un campione casuale di righe da includere nel training set. Devi solo fornirle il numero totale di osservazioni e quante te ne servono per il training.
Usa il vettore risultante di ID di riga per suddividere loans in insiemi di dati di training e di test. Il dataset loans è a tua disposizione.
Questo esercizio fa parte del corso
Apprendimento supervisionato in R: Classificazione
Istruzioni dell'esercizio
- Applica la funzione
nrow()per determinare quante osservazioni ci sono nel datasetloanse quante servono per un campione al 75%. - Usa la funzione
sample()per creare un vettore di interi con gli ID di riga per il campione al 75%. Il primo argomento disample()deve essere il numero di righe del dataset, il secondo è il numero di righe di cui hai bisogno nel training set. - Suddividi i dati
loansusando gli ID di riga per creare il dataset di training. Salvalo comeloans_train. - Suddividi di nuovo
loans, ma questa volta seleziona tutte le righe che non sono insample_rows. Salvalo comeloans_test
esercizio interattivo pratico
Prova questo esercizio completando questo codice di esempio.
# Determine the number of rows for training
# Create a random sample of row IDs
sample_rows <- sample(___, ___)
# Create the training dataset
loans_train <- loans[___]
# Create the test dataset
loans_test <- loans[___]