Relational Neighbor Classifier
In questo esercizio applicherai un semplice classificatore basato sulla rete chiamato relational neighbor classifier.
Usa le etichette di classe dei nodi vicini per calcolare una probabilità di churn per ogni nodo della rete.
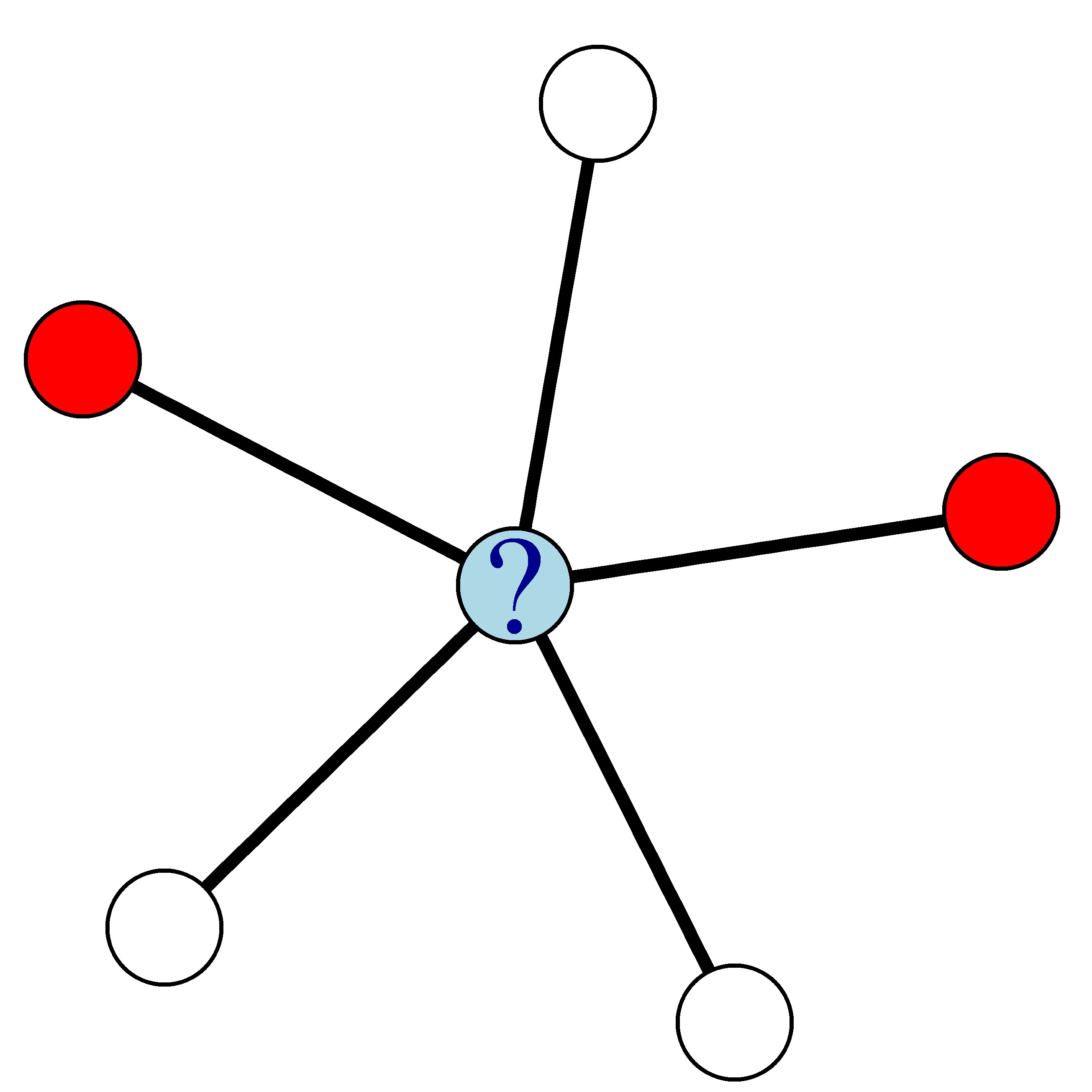
Per esempio, nella rete qui sotto, in cui i nodi rossi indicano i clienti churner e i nodi bianchi i non-churner, la probabilità di churn del nodo blu è 0,4.
Ti vengono forniti due vettori: ChurnNeighbors e NonChurnNeighbors, con per ciascun cliente il numero di vicini che hanno abbandonato e che non hanno abbandonato, rispettivamente.
Questo esercizio fa parte del corso
Analitica predittiva con dati di rete in R
Istruzioni dell'esercizio
- Calcola la probabilità di churn di ciascun cliente,
churnProb, usando il relational neighbor classifier. - Usa
which()per trovare i clienti con la probabilità di churn più alta. Chiama questo vettoremostLikelyChurners. - Usa
mostLikelyChurnersper trovare gli ID dei clienti con la probabilità di churn più alta.
esercizio interattivo pratico
Prova questo esercizio completando questo codice di esempio.
# Compute the churn probabilities
churnProb <- ___ / (ChurnNeighbors + ___)
# Find who is most likely to churn
mostLikelyChurners <- which(churnProb == ___(churnProb))
# Extract the IDs of the most likely churners
customers$id[___]