Mettre en œuvre la règle de mise à jour du double Q-learning
Le double Q-learning étend l’algorithme de Q-learning pour réduire la surestimation des valeurs d’action en maintenant et en mettant à jour deux tables Q distinctes. En dissociant la sélection de l’action de son évaluation, le double Q-learning fournit une estimation plus précise des valeurs de Q. Dans cet exercice, vous allez implémenter la règle de mise à jour du double Q-learning. Une liste Q contenant deux tables Q a été générée.
La bibliothèque numpy a été importée sous le nom np, et les valeurs de gamma et alpha ont été préchargées. Les formules de mise à jour sont ci-dessous :
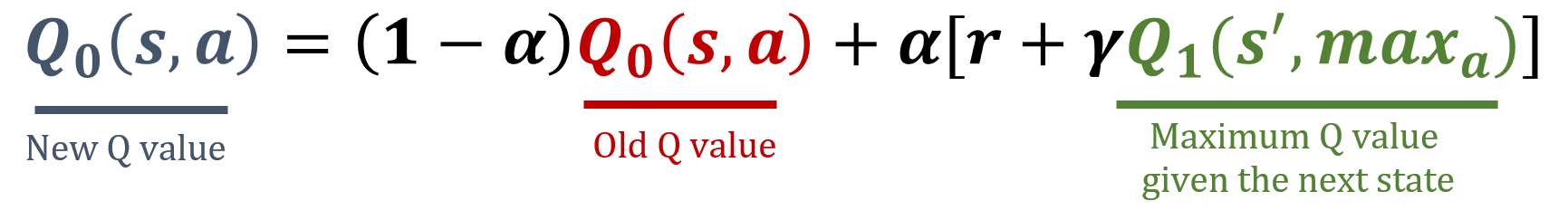
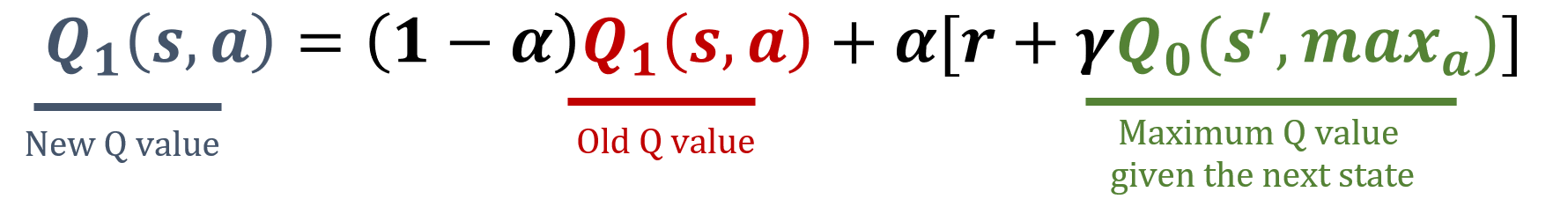
Cet exercice fait partie du cours
<cours>Reinforcement Learning avec Gymnasium en Python</cours>Instructions de l’exercice
- Décidez aléatoirement quelle table Q dans
Qsera mise à jour pour l’estimation de la valeur d’action en calculant son indicei. - Réalisez les étapes nécessaires pour mettre à jour
Q[i].
Exercice interactif pratique
Essayez cet exercice en complétant ce code d’exemple.
Q = [np.random.rand(8,4), np.random.rand(8,4)]
def update_q_tables(state, action, reward, next_state):
# Get the index of the table to update
i = ____
# Update Q[i]
best_next_action = ____
Q[i][state, action] = ____