Règle de mise à jour Expected SARSA
Dans cet exercice, vous allez implémenter la règle de mise à jour Expected SARSA, un algorithme de Machine Learning par renforcement sans modèle basé sur la différence temporelle. Expected SARSA estime la valeur attendue de la politique courante en moyennant sur toutes les actions possibles, ce qui fournit une cible de mise à jour plus stable que SARSA. Les formules utilisées dans Expected SARSA sont présentées ci-dessous.
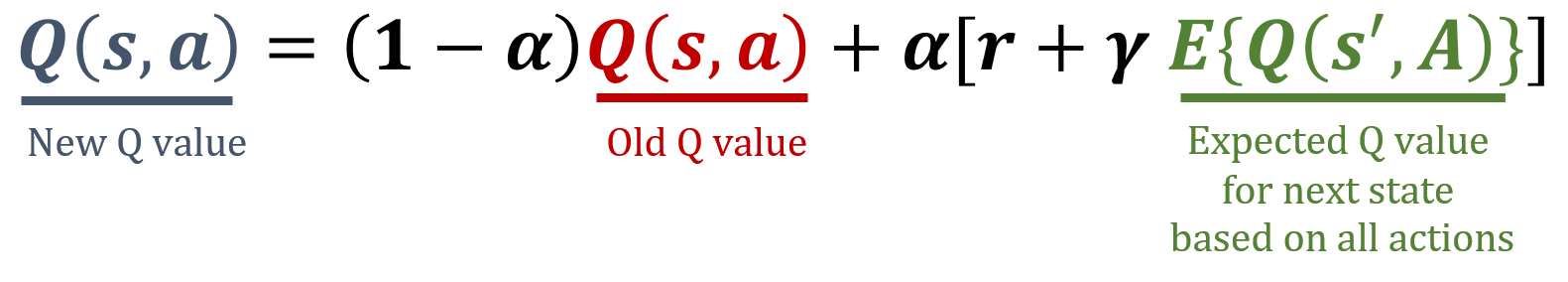
La bibliothèque numpy a été importée sous le nom np.
Cet exercice fait partie du cours
<cours>Reinforcement Learning avec Gymnasium en Python</cours>Instructions de l’exercice
- Calculez la valeur Q attendue pour
next_state. - Mettez à jour la valeur Q pour l’
stateet l’actioncourants en utilisant la formule Expected SARSA. - Mettez à jour la table Q
Qen supposant qu’un agent effectue l’action1dans l’état2, passe à l’état3et reçoit une récompense de5.
Exercice interactif pratique
Essayez cet exercice en complétant ce code d’exemple.
def update_q_table(state, action, next_state, reward):
# Calculate the expected Q-value for the next state
expected_q = ____
# Update the Q-value for the current state and action
Q[state, action] = ____
Q = np.random.rand(5, 2)
print("Old Q:\n", Q)
alpha = 0.1
gamma = 0.99
# Update the Q-table
update_q_table(____, ____, ____, ____)
print("Updated Q:\n", Q)