Matrice de confusion
Avec la fonction confusion_matrix() de scikit-learn, vous pouvez facilement créer la matrice de confusion de votre classifieur et obtenir une vision plus nuancée de ses performances. Elle prend deux arguments : les étiquettes réelles de votre jeu de test — y_test — et vos étiquettes prédites.
Les étiquettes prédites par votre classifieur Random Forest dans l’exercice précédent sont stockées dans y_pred et ont été calculées ainsi :
y_pred = clf.predict(X_test)
Remarque importante : par défaut, sklearn calcule la matrice de confusion comme suit :
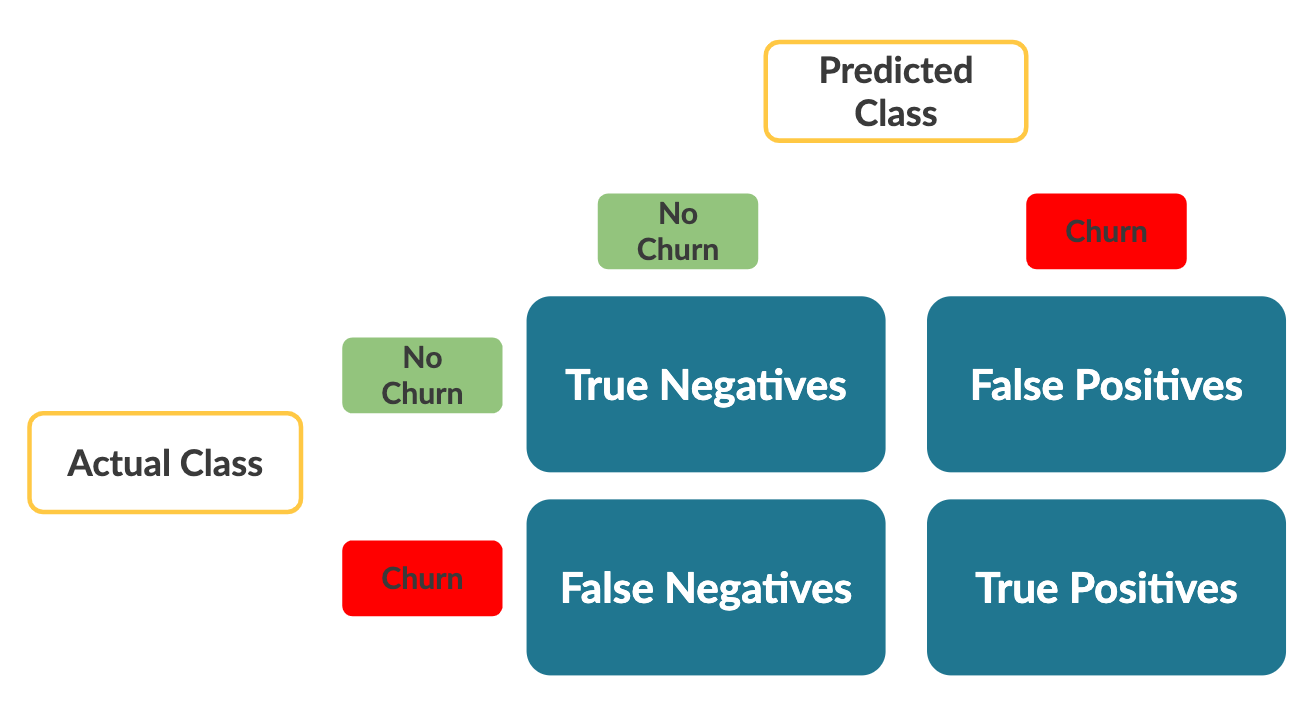
Notez que les axes sont inversés par rapport à ceux vus dans la vidéo. Les métriques restent identiques, mais gardez cela en tête lorsque vous interprétez le tableau.
Cet exercice fait partie du cours
<cours>Marketing Analytics : prédire l’attrition client en Python</cours>Exercice interactif pratique
Essayez cet exercice en complétant ce code d’exemple.
# Import confusion_matrix