Crear conjuntos de datos de prueba aleatorios
Antes de construir un modelo de préstamo más sofisticado, es importante retener una parte de los datos del préstamo para simular lo bien que predecirá los resultados de futuros solicitantes de préstamos.
Como se muestra en la imagen siguiente, puedes utilizar el 75% de las observaciones para el entrenamiento y el 25% para probar el modelo.
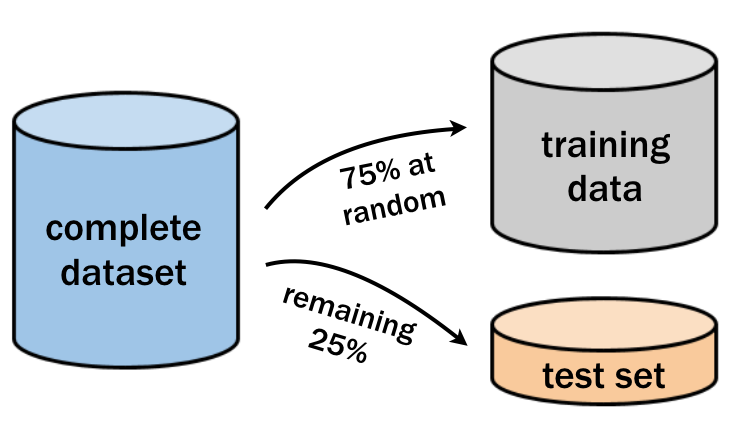
La función sample() puede utilizarse para generar una muestra aleatoria de filas que se incluirán en el conjunto de entrenamiento. Sólo tienes que proporcionarle el número total de observaciones y el número necesario para el entrenamiento.
Utiliza el vector resultante de la fila IDs para subdividir los préstamos en conjuntos de datos de entrenamiento y de prueba. El conjunto de datos loans está disponible para que lo utilices.
Este ejercicio forma parte del curso
Aprendizaje supervisado en R: Clasificación
Instrucciones del ejercicio
- Aplica la función
nrow()para determinar cuántas observaciones hay en el conjunto de datosloans, y el número necesario para una muestra del 75%. - Utiliza la función
sample()para crear un vector entero de fila IDs para la muestra del 75%. El primer argumento desample()debe ser el número de filas del conjunto de datos, y el segundo es el número de filas que necesitas en tu conjunto de entrenamiento. - Subconjunta los datos de
loansutilizando la fila IDs para crear el conjunto de datos de entrenamiento. Guárdalo comoloans_train. - Vuelve a subconjuntar
loans, pero esta vez selecciona todas las filas que no estén ensample_rows. Guárdalo comoloans_test
ejercicio interactivo práctico
Prueba este ejercicio completando este código de ejemplo.
# Determine the number of rows for training
# Create a random sample of row IDs
sample_rows <- sample(___, ___)
# Create the training dataset
loans_train <- loans[___]
# Create the test dataset
loans_test <- loans[___]