Silhouette metoda
V poslední lekci jsi viděl/a, jak různý počet shluků ovlivňuje výkon algoritmu K-Means. V kontextu pohovoru je to obzvlášť důležité – optimální počet shluků totiž přináší nejlepší výsledky.
V tomto cvičení použiješ funkci silhouette_score() z sklearn.metrics na algoritmy K-Means natrénované na DataFrame diabetes, abys pomocí Silhouette metody našel/a optimální počet shluků. Při výpočtu skóre budeš používat euklidovskou vzdálenost, která zajistí srovnatelnost s metodou Elbow.
Matice příznaků X, kterou použiješ k trénování modelů K-Means, je už připravená.
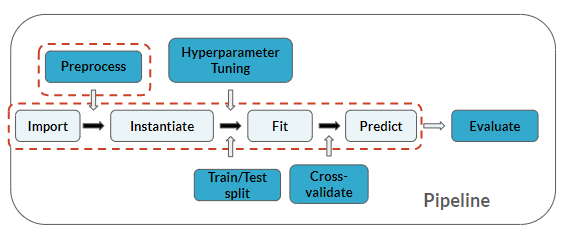
V pipeline jsi na stejném místě jako v předchozích cvičeních, ale tentokrát přidáš také krok predikce:
Toto cvičení je součástí kurzu
Procvičování otázek k pohovorům z oblasti Machine Learning v Pythonu
Interaktivní cvičení na vyzkoušení si v praxi
Vyzkoušejte si toto cvičení dokončením tohoto ukázkového kódu.
# Import modules
from sklearn.____ import ____
from sklearn.____ import ____