Základní klasifikátor s logistickou regresí
V posledních 2 lekcích sis ukázal/a, jak důležitý je výběr příznaků v kontextu Machine Learning pohovorů. Další okruh otázek, na které se při takovém pohovoru určitě narazíš, se týká feature engineeringu a toho, jak pomáhá zlepšit výkon modelu.
V tomto cvičení vytvoříš nový příznak z datasetu loan_data z 1. kapitoly, porovnáš skóre přesnosti modelů logistické regrese na datech před feature engineeringem a po něm, a to porovnáním testovacích štítků s předpovězenými hodnotami cílové proměnné Loan Status.
Všechny potřebné balíčky jsou už naimportované: matplotlib.pyplot jako plt, seaborn jako sns, LogisticRegression z sklearn.linear_model, train_test_split z sklearn.model_selection a accuracy_score z sklearn.metrics.
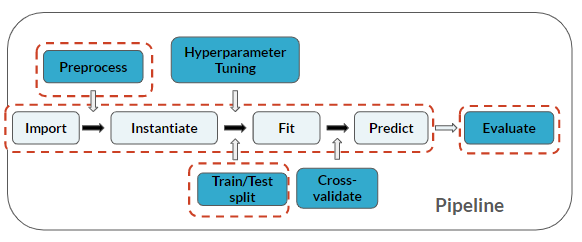
Feature engineering je považován za krok předzpracování dat před samotným modelováním:
Toto cvičení je součástí kurzu
Procvičování otázek k pohovorům z oblasti Machine Learning v Pythonu
Interaktivní cvičení na vyzkoušení si v praxi
Vyzkoušejte si toto cvičení dokončením tohoto ukázkového kódu.
# Create X matrix and y array
X = loan_data.____("____", axis=1)
y = loan_data["____"]
# Train/test split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=123)
# Instantiate
logistic = ____()
# Fit
logistic.____(____, ____)
# Predict and print accuracy
print(____(y_true=____, y_pred=logistic.____(____)))