Implementing double Q-learning update rule
Double Q-learning is an extension of the Q-learning algorithm that helps to reduce overestimation of action values by maintaining and updating two separate Q-tables. By decoupling the action selection from the action evaluation, Double Q-learning provides a more accurate estimation of the Q-values. This exercise guides you through implementing the Double Q-learning update rule. A list Q containing two Q-tables has been generated.
The numpy library has been imported as np, and gamma and alpha values have been pre-loaded. The update formulas are below:
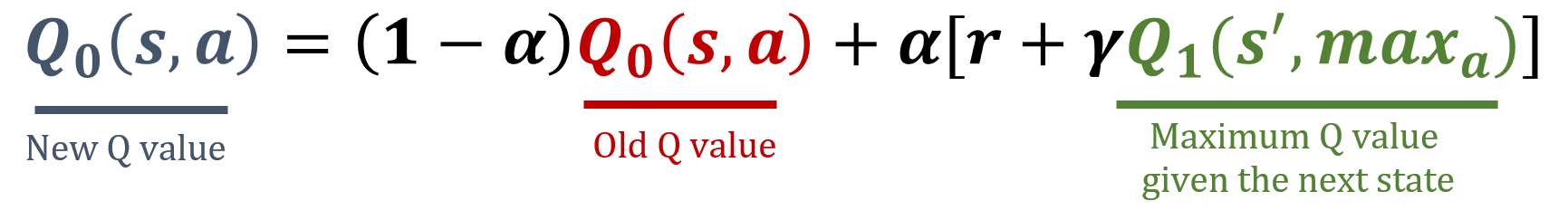
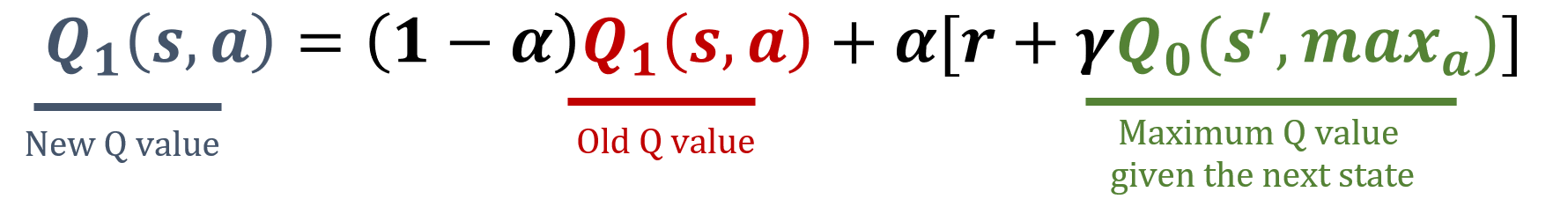
This exercise is part of the course
Reinforcement Learning with Gymnasium in Python
Exercise instructions
- Randomly decide which Q-table within
Qto update for the action value estimation by computing its indexi. - Perform the necessary steps to update
Q[i].
Hands-on interactive exercise
Have a go at this exercise by completing this sample code.
Q = [np.random.rand(8,4), np.random.rand(8,4)]
def update_q_tables(state, action, reward, next_state):
# Get the index of the table to update
i = ____
# Update Q[i]
best_next_action = ____
Q[i][state, action] = ____