Expected SARSA update rule
In this exercise, you'll implement the Expected SARSA update rule, a temporal difference model-free RL algorithm. Expected SARSA estimates the expected value of the current policy by averaging over all possible actions, providing a more stable update target compared to SARSA. The formulas used in Expected SARSA can be found below.
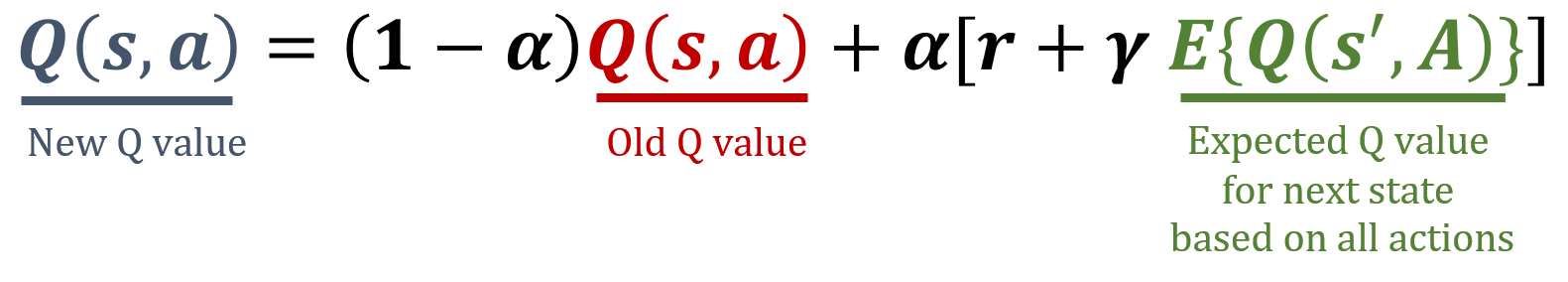
The numpy library has been imported as np.
This exercise is part of the course
Reinforcement Learning with Gymnasium in Python
Exercise instructions
- Calculate the expected Q-value for the
next_state. - Update the Q-value for the current
stateandactionusing the Expected SARSA formula. - Update the Q-table
Qsupposing that an agent takes action1in state2and moves to state3, receiving a reward of5.
Hands-on interactive exercise
Have a go at this exercise by completing this sample code.
def update_q_table(state, action, next_state, reward):
# Calculate the expected Q-value for the next state
expected_q = ____
# Update the Q-value for the current state and action
Q[state, action] = ____
Q = np.random.rand(5, 2)
print("Old Q:\n", Q)
alpha = 0.1
gamma = 0.99
# Update the Q-table
update_q_table(____, ____, ____, ____)
print("Updated Q:\n", Q)