Treinando o modelo baseado em word embedding
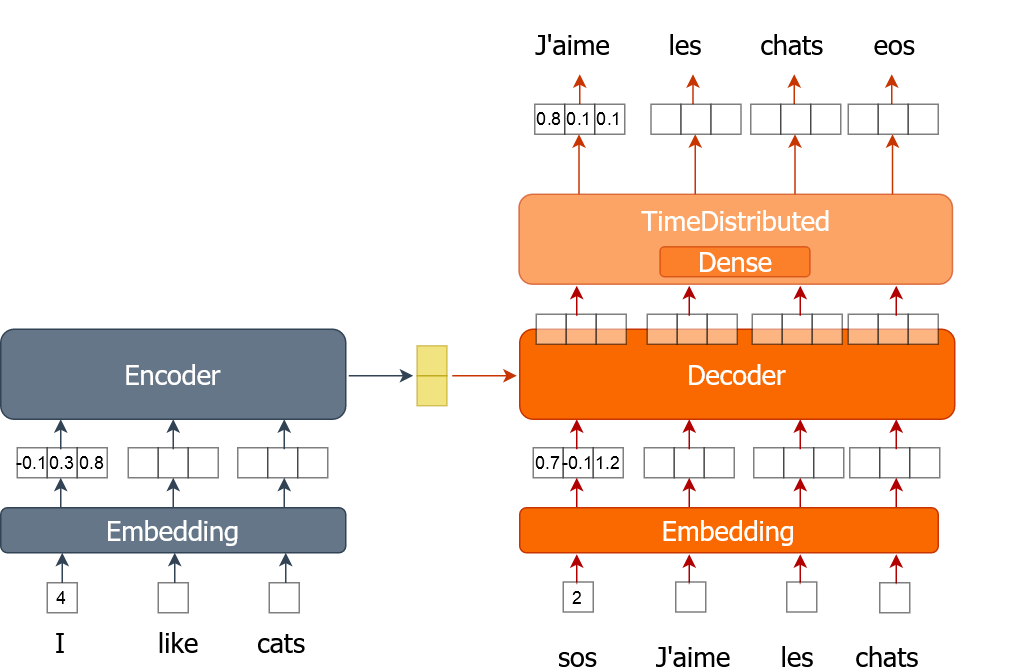
Aqui você vai aprender como implementar o processo de treinamento de um modelo de tradução automática que usa word embeddings. Uma palavra é representada por um único número, em vez de um vetor one-hot, como você fez nos exercícios anteriores. Você vai treinar o modelo por várias épocas, percorrendo o conjunto de dados completo em lotes.
Para este exercício, você recebe dados de treinamento (tr_en e tr_fr) na forma de uma lista de sentenças. Você usará apenas uma amostra bem pequena (1000 sentenças) dos dados reais, pois o treinamento completo pode levar muito tempo. Você também tem a função sents2seqs() e o modelo nmt_emb, que implementou no exercício anterior. Lembre-se de que usamos en_x para nos referirmos às entradas do codificador (encoder) e de_x às entradas do decodificador (decoder).
Este exercicio faz parte do curso
Machine Translation with Keras
Instruções do exercicio
- Obtenha um único lote de sentenças em francês sem onehot encoding usando a função
sents2seqs(). - Pegue todas as palavras, exceto a última, de
de_xy. - Pegue todas as palavras, exceto a primeira, de
de_xy_oh(palavras em francês com onehot encoding). - Treine o modelo usando um único lote de dados
exercicio interativo prático
Tente este exercicio completando este código de exemplo.
for ei in range(3):
for i in range(0, train_size, bsize):
en_x = sents2seqs('source', tr_en[i:i+bsize], onehot=False, reverse=True)
# Get a single batch of French sentences with no onehot encoding
de_xy = ____('target', ____[i:i+bsize], ____=____)
# Get all words except the last word in that batch
de_x = de_xy[:,____]
de_xy_oh = sents2seqs('target', tr_fr[i:i+bsize], onehot=True)
# Get all words except the first from de_xy_oh
de_y = de_xy_oh[____,____,____]
# Training the model on a single batch of data
nmt_emb.train_on_batch([____,____], ____)
res = nmt_emb.evaluate([en_x, de_x], de_y, batch_size=bsize, verbose=0)
print("{} => Loss:{}, Train Acc: {}".format(ei+1,res[0], res[1]*100.0))