Etapas de um pipeline de dados
Um dos seus pipelines de dados mais críticos para o negócio na Sierra Publishing depende de um fluxo de alta velocidade, vindo de um stream de dados Kafka. Precisamos ler esses dados e fazer junções com alguns outros conjuntos de dados.
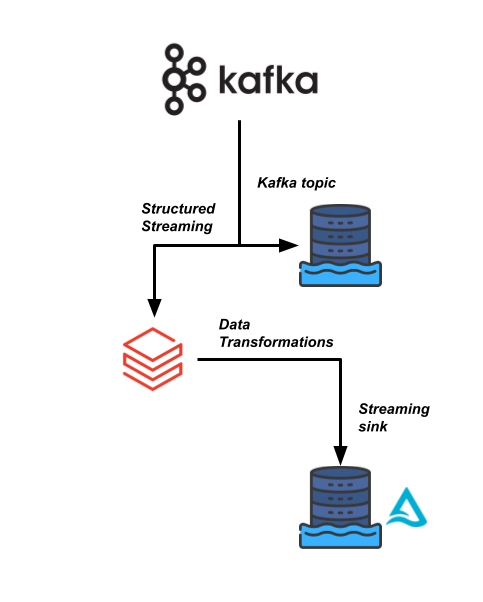
Sua equipe de engenharia de dados quer usar o Databricks para tornar esse pipeline mais eficiente e permitir que os consumidores a jusante leiam esses dados em tempo real para suas análises.
Este exercicio faz parte do curso
Conceitos de Databricks
exercicio interativo prático
Transforme teoria em prática com um dos nossos exercicio interativos
 Iniciar exercicio
Iniciar exercicio