Predictieve verdeling
Goed gedaan met het analyseren van de parameter-trekkingen! Laten we nu het lineaire regressiemodel gebruiken om voorspellingen te maken. Hoeveel klikken kun je verwachten als je 10 kledingadvertenties en 10 sneakeradvertenties laat zien? Om dat te achterhalen, moet je trekken uit de predictieve verdeling: een normale verdeling met het gemiddelde gedefinieerd door de lineaire regressieformule en een standaarddeviatie die door het model is geschat.
Eerst vat je de posterior van elke parameter samen met het gemiddelde. Daarna bereken je het gemiddelde van de predictieve verdeling volgens de regressievergelijking. Vervolgens trek je een steekproef uit de predictieve verdeling en ten slotte plot je de dichtheid. Hier is de regressieformule voor je gemak:
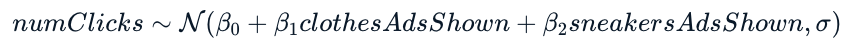
pymc3, numpy en seaborn zijn geïmporteerd onder hun gebruikelijke aliassen.
Deze oefening maakt deel uit van de cursus
Bayesian Data Analysis in Python
Interactieve oefening met praktijkervaring
Probeer deze oefening door deze voorbeeldcode aan te vullen.
# Aggregate posteriors of the parameters to point estimates
intercept_coef = ____
sneakers_coef = ____
clothes_coef = ____
sd_coef = ____