Codifica dei dati
La codifica dei dati categorici li rende utilizzabili dagli algoritmi di Machine Learning. R codifica internamente i fattori, ma la codifica è necessaria quando sviluppi i tuoi modelli.
In questo esercizio, prima costruirai un modello lineare usando lm() e poi svilupperai passo dopo passo un tuo modello.
Nella one hot encoding, viene creata una colonna separata per ciascun livello.
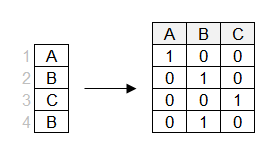
Nota che una delle colonne può essere ricavata dalle altre (ad esempio, 0 nelle colonne "B" e "C" implica 1 nella colonna "A"). Quindi, per la regressione lineare puoi eliminare la prima colonna. Rivedremo i modelli lineari più nel dettaglio nel prossimo capitolo.
Per la one hot encoding, puoi usare dummyVars() dal pacchetto caret.
Per usarla, crea prima l'encoder e poi trasforma l'insieme di dati:
encoder <- dummyVars(~ category, data = df)
predict(encoder, newdata = df)
I casi completi del dataset del sondaggio dal pacchetto MASS sono disponibili come survey.
Il pacchetto caret è già stato caricato.
Questo esercizio fa parte del corso
Esercitarsi con le domande di statistica per i colloqui in R
esercizio interattivo pratico
Prova questo esercizio completando questo codice di esempio.
# Fit a linear model
lm(___ ~ Exer, data = ___)