Matrice di confusione
Usando la funzione di scikit-learn confusion_matrix(), puoi creare facilmente la matrice di confusione del tuo classificatore e ottenere una comprensione più sfumata delle sue prestazioni. Richiede due argomenti: le etichette reali del tuo insieme di test - y_test - e le etichette previste.
Le etichette previste del tuo classificatore Random Forest dell'esercizio precedente sono salvate in y_pred e sono state calcolate così:
y_pred = clf.predict(X_test)
Nota importante: per impostazione predefinita, sklearn calcola la matrice di confusione come segue:
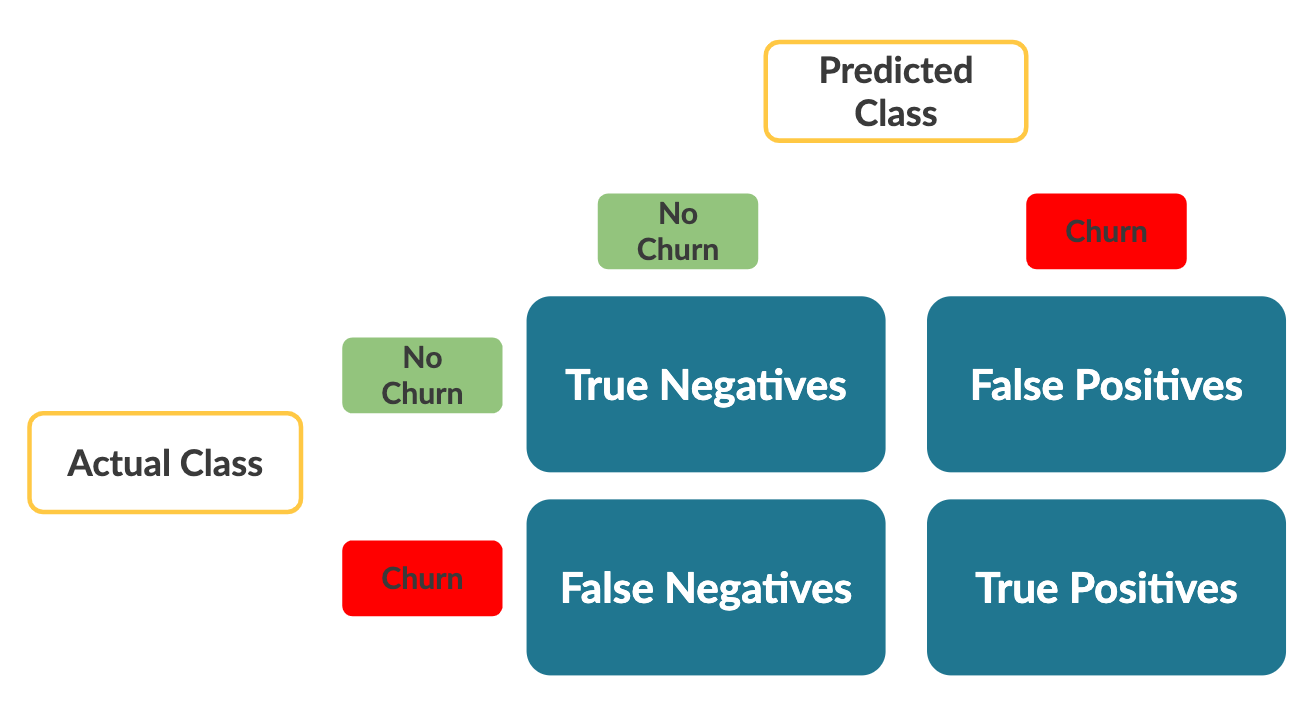
Nota che gli assi sono l'opposto di quanto visto nel video. Le metriche rimangono le stesse, ma tienilo a mente quando interpreti la tabella.
Questo esercizio fa parte del corso
Marketing Analytics: Prevedere il churn dei clienti in Python
esercizio interattivo pratico
Prova questo esercizio completando questo codice di esempio.
# Import confusion_matrix