Forza della correlazione
In modo intuitivo, possiamo guardare i grafici forniti e "vedere" se le due variabili sembrano "variare insieme".
- Insieme di dati A: x e y cambiano insieme e sembrano avere una relazione forte.
- Insieme di dati B: c’è una tendenza crescente approssimativa; x e y sembrano solo debolmente correlate.
- Insieme di dati C: sembra una dispersione casuale; x e y non sembrano cambiare insieme e sono non correlate.
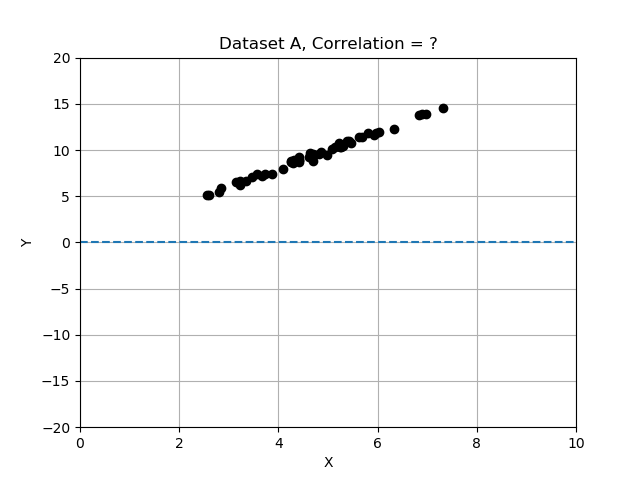
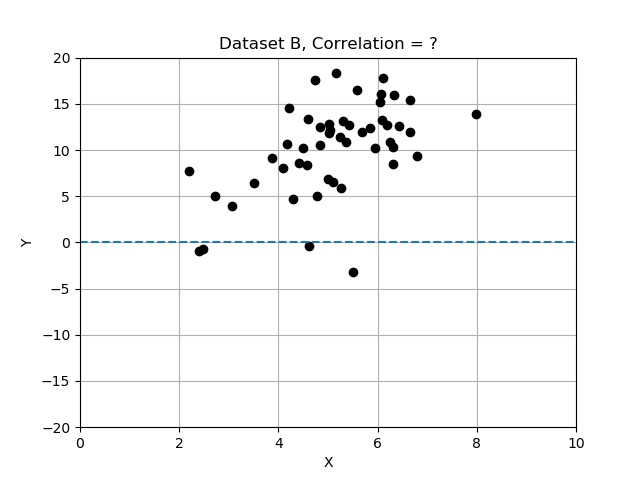
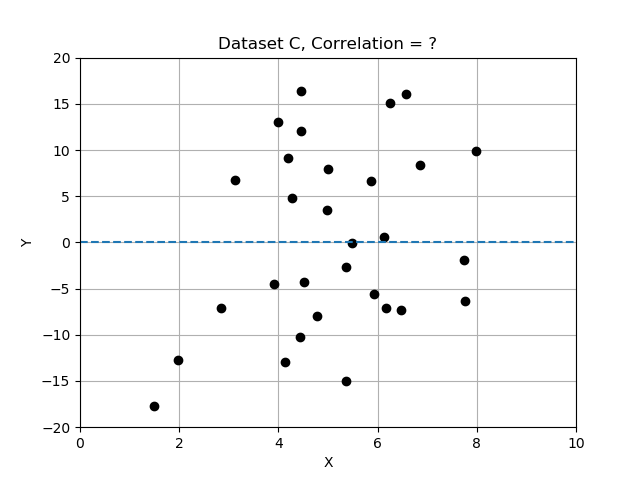
Ricorda che le deviazioni differiscono dalla media e che abbiamo normalizzato dividendo le deviazioni per la deviazione standard. In questo esercizio confronterai i 3 insiemi di dati calcolando la correlazione e determinando quale insieme di dati ha le variabili x e y più fortemente correlate. Usa la tabella dati data_sets, un dizionario di record, ognuno con le chiavi 'name', 'x', 'y' e 'correlation'.
Questo esercizio fa parte del corso
Introduzione alla modellazione lineare in Python
Istruzioni dell'esercizio
- Completa la definizione della funzione
correlation()usando la media dei prodotti delle deviazioni normalizzate dixey. - Itera su
data_sets, calcolando e salvando ogni correlazione concorrelation(record['x'], record['y']). - Esegui il codice fino a questo punto (cioè alla fine del ciclo for) e controlla l’output stampato. Quale insieme di dati ha la correlazione più forte?
- Assegna il nome dell’insieme di dati (
data_sets['A'],data_sets['B']odata_sets['C']) con la correlazione più forte alla variabilebest_data.
esercizio interattivo pratico
Prova questo esercizio completando questo codice di esempio.
# Complete the function that will compute correlation.
def correlation(x,y):
x_dev = x - np.____(x)
y_dev = y - np.____(y)
x_norm = x_dev / np.____(x)
y_norm = y_dev / np.____(y)
return np.____(x_norm * y_norm)
# Compute and store the correlation for each data set in the list.
for name, data in data_sets.items():
data['correlation'] = ____(data['x'], data['y'])
print('data set {} has correlation {:.2f}'.format(name, data['correlation']))
# Assign the data set with the best correlation.
best_data = data_sets['____']