Buchstaben des genetischen Codes
Die grundlegenden Bausteine der RNA sind vier Moleküle, die jeweils durch einen einzelnen Buchstaben beschrieben werden: Adenin (A), Cytosin (C), Guanin (G) und Uracil (U). Die Information, die ein RNA-Strang trägt, lässt sich als lange Folge dieser vier Buchstaben darstellen. Um diesen Code zu lesen, teilt man die Kette in Folgen von jeweils drei Buchstaben (z. B. GCU, ACG, …). Diese Dreierfolgen nennt man Codons. Das Konzept ist in der Abbildung unten dargestellt.
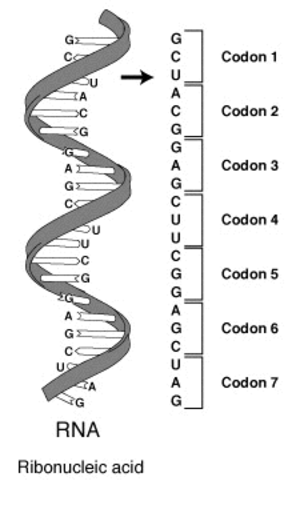
Dein Ziel in dieser Übung ist es, aus einem Vektor mit den vier Buchstaben der RNA-Bausteine einen Data Frame mit allen möglichen Dreierfolgen (Codons) zu erstellen.
Diese Übung ist Teil des Kurses
<Kurs>Daten umformen mit tidyr</Kurs>Interaktive praktische Übung
Versuche dich an dieser Übung, indem du diesen Beispielcode vervollständigst.
letters <- c("A", "C", "G", "U")
# Create a tibble with all possible 3 way combinations
codon_df <- ___
codon_df