Training des auf Wort-Embeddings basierenden Modells
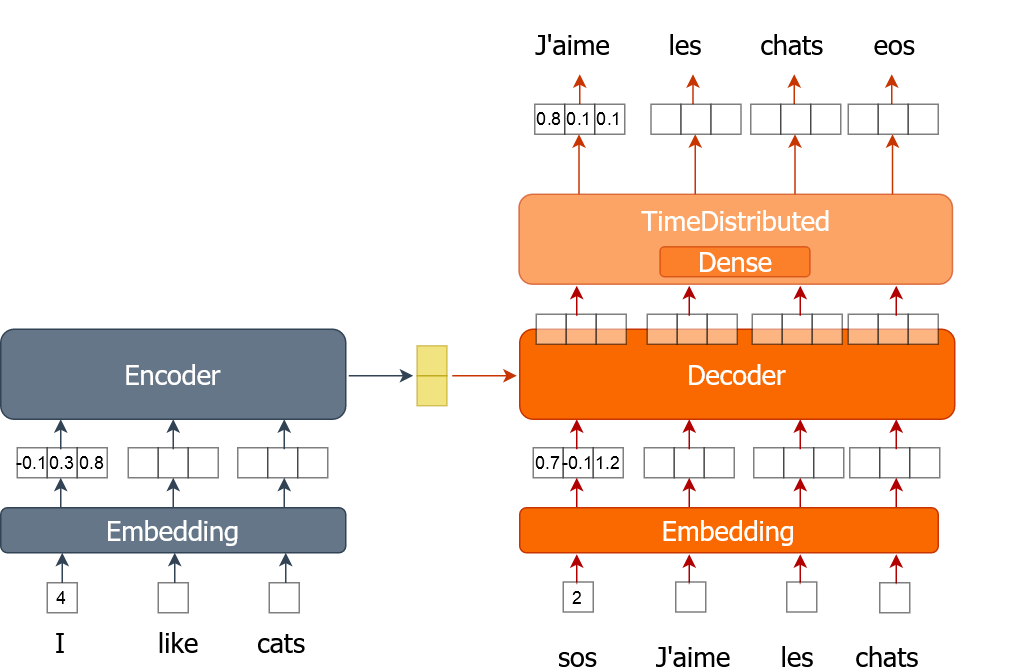
Hier erfährst du, wie du den Trainingsprozess für ein maschinelles Übersetzungsmodell mit Wort-Embeddings umsetzt. Ein Wort wird als einzelne Zahl dargestellt, nicht als One-Hot-codierter Vektor, wie du es in den vorherigen Übungen gemacht hast. Du trainierst das Modell über mehrere Epochen hinweg, während du den gesamten Datensatz in Stapeln durchläufst.
Für diese Übung bekommst du Trainingsdaten (tr_en und tr_fr) in Form einer Liste von Sätzen. Du wirst nur einen ganz kleinen Teil (1000 Sätze) der echten Daten verwenden, weil das Training sonst echt lange dauern kann. Du hast auch die Funktion „ sents2seqs() ” und das Modell „ nmt_emb ”, die du in der letzten Übung gemacht hast. Denk dran, dass wir „ en_x “ für Encoder-Eingänge und „ de_x “ für Decoder-Eingänge verwenden.
Diese Übung ist Teil des Kurses
<Kurs>Maschinelle Übersetzung mit Keras</Kurs>Übungsanweisungen
- Hol dir mit der Funktion „
sents2seqs()“ einen einzelnen Satz französischer Sätze ohne One-Hot-Kodierung. - Nimm alle Wörter außer dem letzten von
de_xy. - Hol dir alle Wörter außer dem ersten von
de_xy_oh(französische Wörter mit Onehot-Kodierung). - Trainiere das Modell mit einem einzigen Datenbatch.
Interaktive praktische Übung
Versuche dich an dieser Übung, indem du diesen Beispielcode vervollständigst.
for ei in range(3):
for i in range(0, train_size, bsize):
en_x = sents2seqs('source', tr_en[i:i+bsize], onehot=False, reverse=True)
# Get a single batch of French sentences with no onehot encoding
de_xy = ____('target', ____[i:i+bsize], ____=____)
# Get all words except the last word in that batch
de_x = de_xy[:,____]
de_xy_oh = sents2seqs('target', tr_fr[i:i+bsize], onehot=True)
# Get all words except the first from de_xy_oh
de_y = de_xy_oh[____,____,____]
# Training the model on a single batch of data
nmt_emb.train_on_batch([____,____], ____)
res = nmt_emb.evaluate([en_x, de_x], de_y, batch_size=bsize, verbose=0)
print("{} => Loss:{}, Train Acc: {}".format(ei+1,res[0], res[1]*100.0))