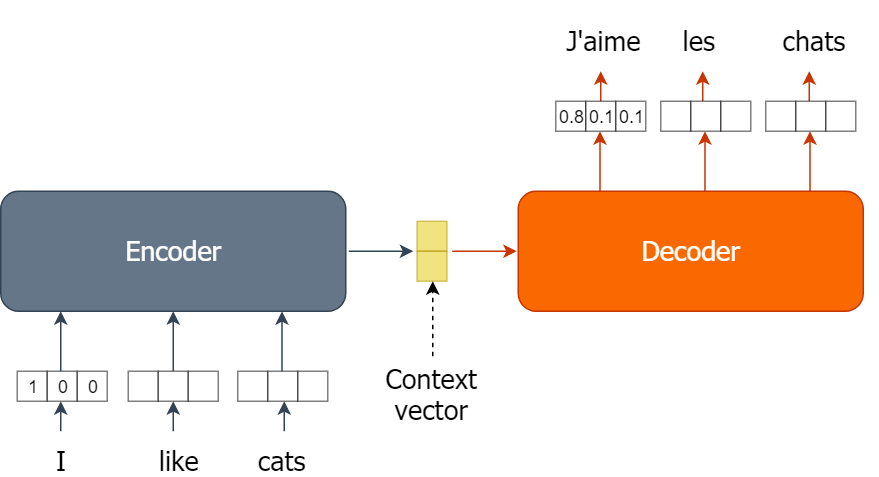
Teil 1: Textumkehrmodell – Encoder
Ein einfaches Modell zum Umkehren von Text zu erstellen ist eine super Methode, um die Mechanismen von Encoder-Decoder-Modellen und deren Zusammenhänge zu verstehen. Jetzt wirst du den Encoder-Teil eines Textumkehrmodells umsetzen.
Die Umsetzung des Encoders wurde auf zwei Übungen aufgeteilt. In dieser Übung definierst du die Hilfsfunktion „ words2onehot() “. Die Funktion „ words2onehot() “ sollte eine Liste von Wörtern und ein Wörterbuch „ word2index “ nehmen und die Liste der Wörter in ein Array von One-Hot-Vektoren umwandeln. Das Wörterbuch „ word2index “ ist im Arbeitsbereich verfügbar.
Diese Übung ist Teil des Kurses
<Kurs>Maschinelle Übersetzung mit Keras</Kurs>Übungsanweisungen
- Wörter mit dem Wörterbuch „
word2index“ in der Funktion „words2onehot()“ in IDs umwandeln - Wandelt Wort-IDs in One-Hot-Vektoren mit der Länge
3um (mit dem Argument „num_classes“) und gibt das resultierende Array zurück. - Ruf die Funktion „
words2onehot()“ mit den Wörtern „I“, „like“ und „cats“ auf und speicher das Ergebnis in „onehot“. - Druck die Wörter und die dazugehörigen One-Hot-Vektoren mit den Funktionen „
print()“ und „zip()“. Mit der Funktion „zip()“ kannst du mehrere Listen gleichzeitig durchlaufen.
Interaktive praktische Übung
Versuche dich an dieser Übung, indem du diesen Beispielcode vervollständigst.
import numpy as np
def words2onehot(word_list, word2index):
# Convert words to word IDs
word_ids = [____[w] for w in ____]
# Convert word IDs to onehot vectors and return the onehot array
onehot = ____(____, num_classes=3)
return ____
words = ["I", "like", "cats"]
# Convert words to onehot vectors using words2onehot
onehot = ____(____, ____)
# Print the result as (, ) tuples
print([(w,ohe.tolist()) for ____,____ in zip(words, ____)])