The policy network architecture
Build the architecture for a Policy Network that you can use later to train your policy gradient agent.
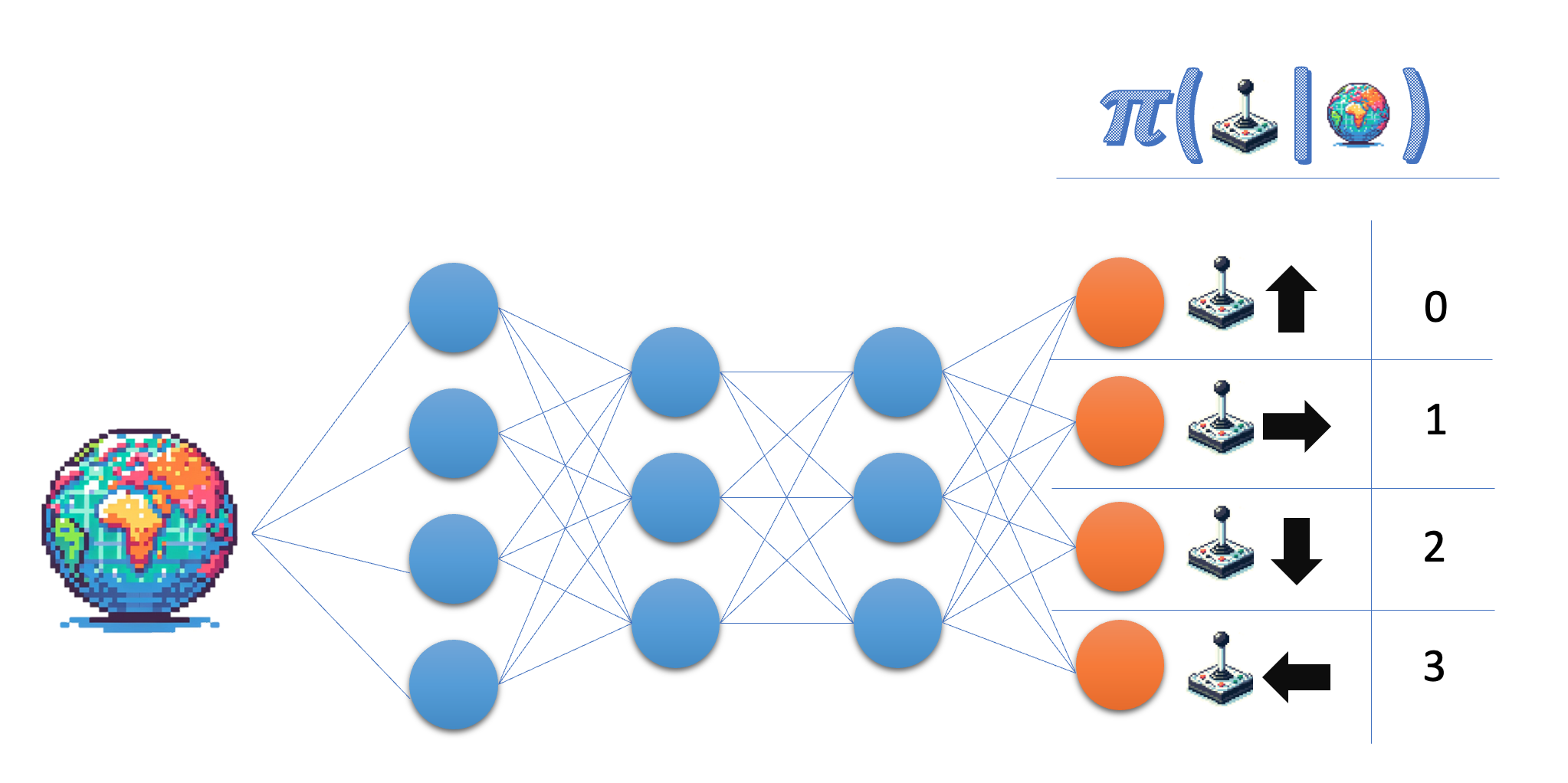
The policy network takes the state as input, and outputs a probability in the action space. For the Lunar Lander environment, you work with four discrete actions, so you want your network to output a probability for each of those actions.
This exercise is part of the course
Deep Reinforcement Learning in Python
Exercise instructions
- Indicate the size for the output layer of the policy network; for flexibility, use the variable name rather than the actual number.
- Ensure the final layer returns probabilities.
Hands-on interactive exercise
Have a go at this exercise by completing this sample code.
class PolicyNetwork(nn.Module):
def __init__(self, state_size, action_size):
super(PolicyNetwork, self).__init__()
self.fc1 = nn.Linear(state_size, 64)
self.fc2 = nn.Linear(64, 64)
# Give the desired size for the output layer
self.fc3 = nn.Linear(64, ____)
def forward(self, state):
x = torch.relu(self.fc1(torch.tensor(state)))
x = torch.relu(self.fc2(x))
# Obtain the action probabilities
action_probs = ____(self.fc3(x), dim=-1)
return action_probs
policy_network = PolicyNetwork(8, 4)
action_probs = policy_network(state)
print('Action probabilities:', action_probs)