The clipped surrogate objective function
Implement the calculate_loss() function for PPO. This requires coding the key innovation of PPO - the clipped surrogate loss function. It helps constrain the policy update to prevent it from moving too far away from the previous policy on each step.
The formula for the clipped surrogate objective is
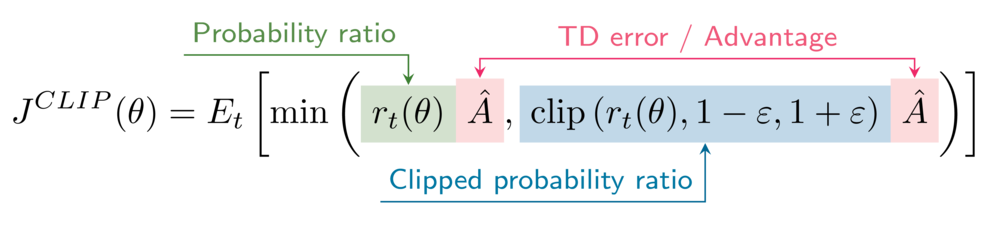
Your environment has the clipping hyperparameter epsilon set to 0.2.
This exercise is part of the course
Deep Reinforcement Learning in Python
Exercise instructions
- Obtain the probability ratios between
\pi_\thetaand\pi_{\theta_{old}}(unclipped and clipped versions). - Calculate the surrogate objectives (unclipped and clipped versions).
- Calculate the PPO clipped surrogate objective.
- Calculate the actor loss.
Hands-on interactive exercise
Have a go at this exercise by completing this sample code.
def calculate_losses(critic_network, action_log_prob, action_log_prob_old,
reward, state, next_state, done):
value = critic_network(state)
next_value = critic_network(next_state)
td_target = (reward + gamma * next_value * (1-done))
td_error = td_target - value
# Obtain the probability ratios
____, ____ = calculate_ratios(action_log_prob, action_log_prob_old, epsilon=.2)
# Calculate the surrogate objectives
surr1 = ratio * ____.____()
surr2 = clipped_ratio * ____.____()
# Calculate the clipped surrogate objective
objective = torch.min(____, ____)
# Calculate the actor loss
actor_loss = ____
critic_loss = td_error ** 2
return actor_loss, critic_loss
actor_loss, critic_loss = calculate_losses(critic_network, action_log_prob, action_log_prob_old,
reward, state, next_state, done)
print(actor_loss, critic_loss)