Kırpılmış yerine geçen amaç fonksiyonu
PPO için calculate_loss() fonksiyonunu uygula. Bu, PPO'nun temel yeniliği olan kırpılmış yerine geçen kayıp fonksiyonunu kodlamanı gerektirir. Bu fonksiyon, politika güncellemesini kısıtlayarak her adımda önceki politikadan çok uzaklaşmasını engeller.
Kırpılmış yerine geçen amacın formülü şöyledir
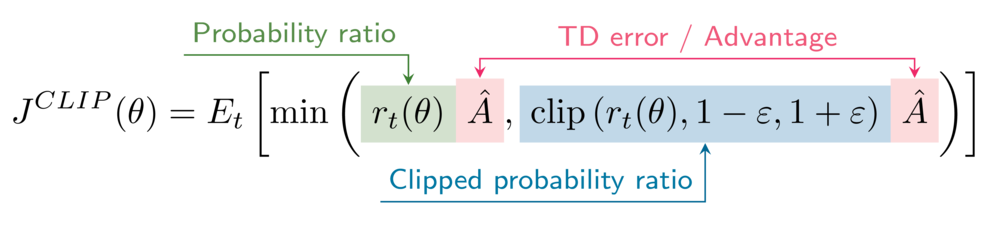
Ortamında kırpma hiperparametresi epsilon 0.2 olarak ayarlanmıştır.
Bu egzersiz, kursun bir parçasıdır
Python ile Deep Reinforcement Learning
Egzersiz talimatları
\pi_\thetaile\pi_{\theta_{old}}arasındaki olasılık oranlarını (kırpılmamış ve kırpılmış sürümler) elde et.- Yerine geçen amaçları (kırpılmamış ve kırpılmış sürümler) hesapla.
- PPO kırpılmış yerine geçen amacı hesapla.
- Aktör kaybını hesapla.
Uygulamalı etkileşimli egzersiz
Bu egzersizi bu örnek kodu tamamlayarak deneyin.
def calculate_losses(critic_network, action_log_prob, action_log_prob_old,
reward, state, next_state, done):
value = critic_network(state)
next_value = critic_network(next_state)
td_target = (reward + gamma * next_value * (1-done))
td_error = td_target - value
# Obtain the probability ratios
____, ____ = calculate_ratios(action_log_prob, action_log_prob_old, epsilon=.2)
# Calculate the surrogate objectives
surr1 = ratio * ____.____()
surr2 = clipped_ratio * ____.____()
# Calculate the clipped surrogate objective
objective = torch.min(____, ____)
# Calculate the actor loss
actor_loss = ____
critic_loss = td_error ** 2
return actor_loss, critic_loss
actor_loss, critic_loss = calculate_losses(critic_network, action_log_prob, action_log_prob_old,
reward, state, next_state, done)
print(actor_loss, critic_loss)