Policy ağının mimarisi
Daha sonra policy gradient ajanını eğitmek için kullanabileceğin bir Policy Ağı mimarisi oluştur.
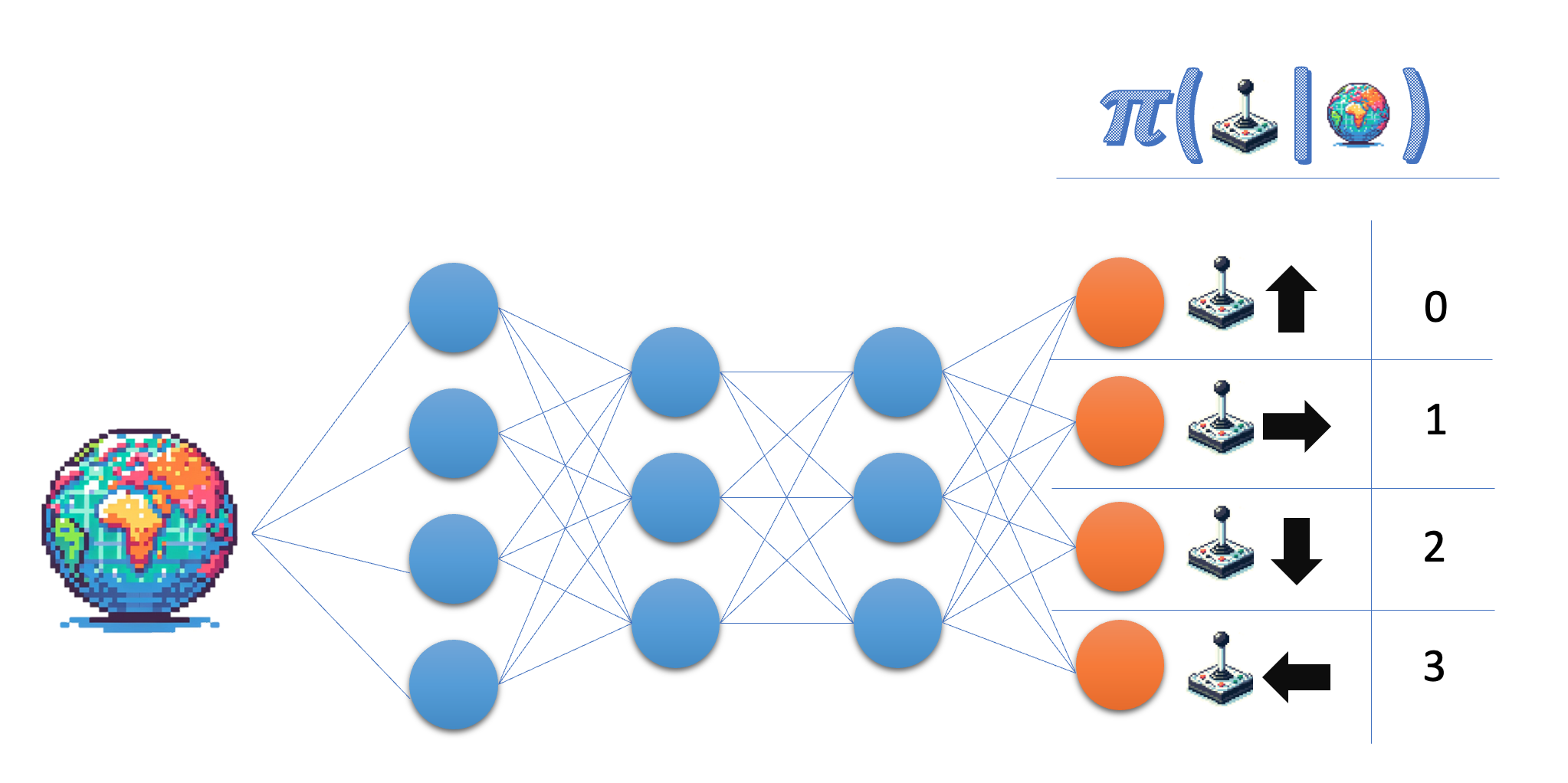
Policy ağı durumu girdi olarak alır ve eylem uzayında bir olasılık çıktılar. Lunar Lander ortamında dört ayrık eylemle çalışırsın; bu yüzden ağının bu eylemlerin her biri için birer olasılık üretmesini istersin.
Bu egzersiz, kursun bir parçasıdır
Python ile Deep Reinforcement Learning
Egzersiz talimatları
- Policy ağının çıktı katmanı için boyutu belirt; esneklik için gerçek sayı yerine değişken adını kullan.
- Son katmanın olasılık döndürdüğünden emin ol.
Uygulamalı etkileşimli egzersiz
Bu egzersizi bu örnek kodu tamamlayarak deneyin.
class PolicyNetwork(nn.Module):
def __init__(self, state_size, action_size):
super(PolicyNetwork, self).__init__()
self.fc1 = nn.Linear(state_size, 64)
self.fc2 = nn.Linear(64, 64)
# Give the desired size for the output layer
self.fc3 = nn.Linear(64, ____)
def forward(self, state):
x = torch.relu(self.fc1(torch.tensor(state)))
x = torch.relu(self.fc2(x))
# Obtain the action probabilities
action_probs = ____(self.fc3(x), dim=-1)
return action_probs
policy_network = PolicyNetwork(8, 4)
action_probs = policy_network(state)
print('Action probabilities:', action_probs)