Método da silhueta
Na última lição, você viu como diferentes quantidades de clusters afetam o desempenho do seu algoritmo de K-Means. Isso é especialmente relevante em uma entrevista, já que o número ideal de clusters gera os melhores resultados.
Neste exercício, você usará a função silhouette_score() de sklearn.metrics em algoritmos K-Means executados no DataFrame diabetes para aplicar o método da Silhueta e encontrar o número ideal de clusters. Observe que você usará a distância euclidiana ao calcular a pontuação, pois isso garante comparabilidade com o método do cotovelo (Elbow).
A matriz de atributos X que você usará para treinar os modelos de K-Means já foi criada para você.
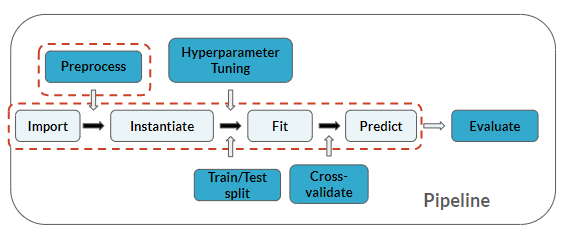
Você está no mesmo ponto do pipeline que nos últimos exercícios, mas aqui vai adicionar a etapa de predição também:
Este exercicio faz parte do curso
Praticando perguntas de entrevista de Machine Learning em Python
exercicio interativo prático
Tente este exercicio completando este código de exemplo.
# Import modules
from sklearn.____ import ____
from sklearn.____ import ____