Modelos de linguagem de visão por prompt (VLMs)
Nos próximos dois exercícios, você vai usar um modelo multimodal pra analisar o sentimento de uma notícia e a imagem correspondente do cabeçalho do conjunto de dados BBC News no Hugging Face:
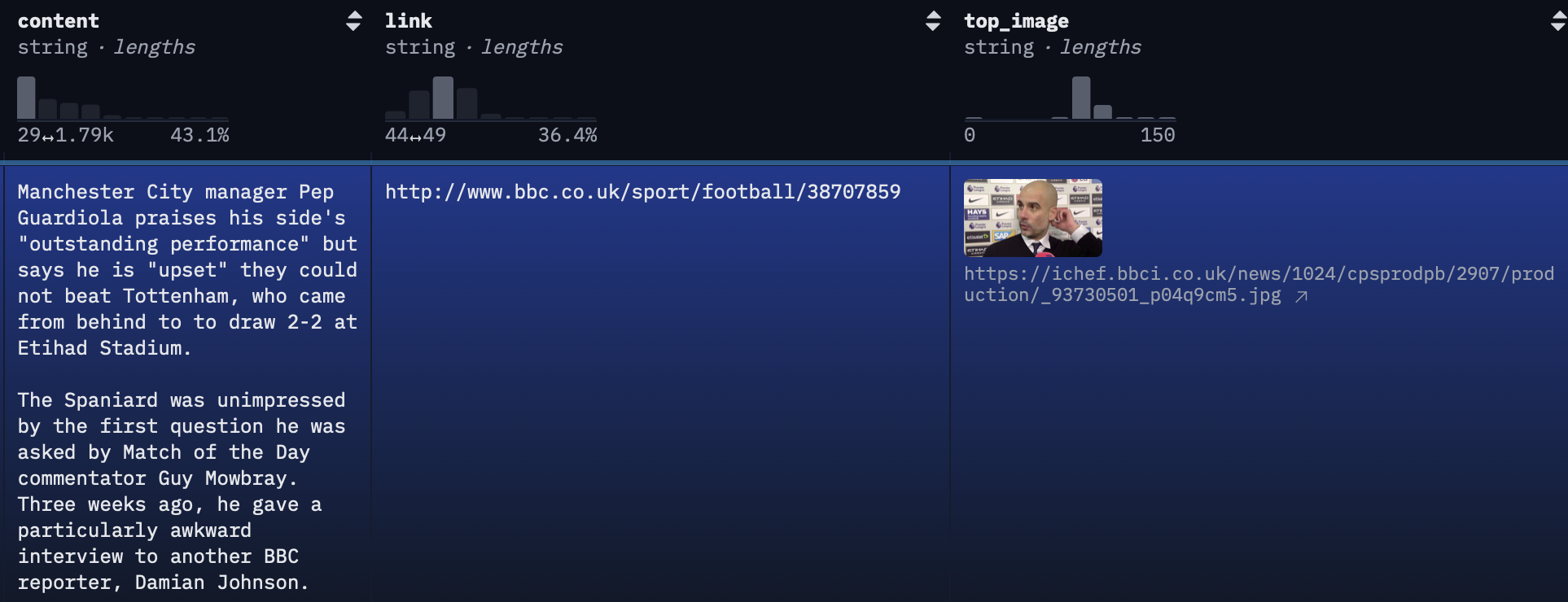
Pra começar, você vai preparar um modelo de chat pro modelo que inclua tanto a imagem quanto a notícia. O conjunto de dados (dataset) e a imagem principal (image) foram carregados.
Este exercicio faz parte do curso
Modelos multimodais com Hugging Face
Instruções do exercicio
- Carregue o conteúdo da notícia (
content) do ponto de dados no índice6nodataset. - Complete a consulta de texto para inserir “
content” em “text_query” usando f-strings. - Adicione
imageetext_queryao modelo de chat, especificando o tipo de conteúdo detext_querycomo"text".
exercicio interativo prático
Tente este exercicio completando este código de exemplo.
# Load the news article content from datapoint 6
content = ____
# Complete the text query
text_query = f"Does the news article have a positive, negative, or neutral impact on championship winning chances: {____}. Provide reasoning."
# Add the text query dictionary to the chat template
chat_template = [
{
"role": "user",
"content": [
{
"type": "image",
"image": ____,
},
____
],
}
]