Use o Spark para dar brilho aos dados
No último exercício, você viu como mover dados do Spark para o pandas. No entanto, talvez você queira ir na outra direção e colocar um DataFrame do pandas em um cluster do Spark! A classe SparkSession também tem um método para isso.
O método .createDataFrame() recebe um DataFrame do pandas e retorna um DataFrame do Spark.
A saída desse método é armazenada localmente, não no catálogo da SparkSession. Isso significa que você pode usar todos os métodos de DataFrames do Spark nele, mas não pode acessar os dados em outros contextos.
Por exemplo, uma consulta SQL (usando o.sql()método) que faça referência ao seu DataFrame vai gerar um erro. Para acessar os dados dessa forma, você precisa salvá-los como uma tabela temporária.
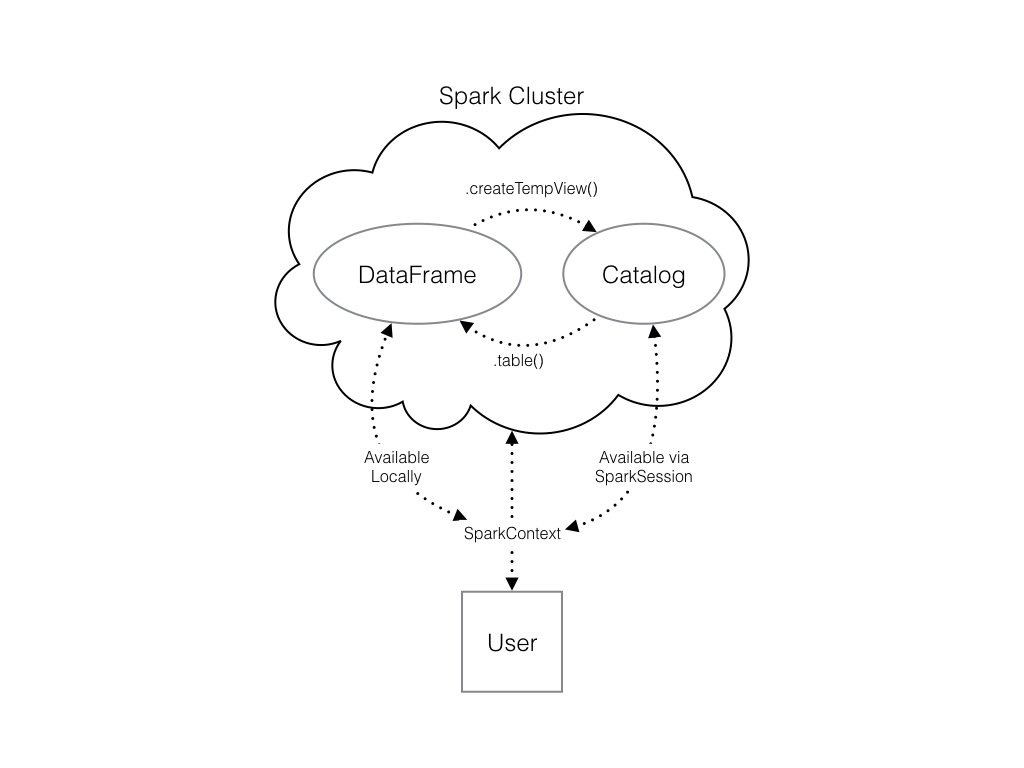
Você pode fazer isso usando o método de DataFrames do Spark .createTempView(), que recebe como único argumento o nome da tabela temporária que você gostaria de registrar. Esse método registra o DataFrame como uma tabela no catálogo, mas, como essa tabela é temporária, só pode ser acessada a partir da SparkSession específica usada para criar o DataFrame do Spark.
Há também o método .createOrReplaceTempView(). Isso cria uma nova tabela temporária com segurança, se não houver nenhuma antes, ou atualiza uma tabela existente, se já houver uma definida. Você deve usar esse método para evitar problemas com tabelas duplicadas.
Confira o diagrama para ver as diferentes maneiras pelas quais as estruturas de dados do Spark interagem.
Já existe uma SparkSession chamada spark em seu espaço de trabalho. numpy foi importado como np e pandas como pd.
Este exercicio faz parte do curso
Fundamentos do PySpark
Instruções do exercicio
- O código para criar um DataFrame do
pandasde números aleatórios já foi fornecido e salvo empd_temp. - Crie um DataFrame do Spark denominado
spark_tempchamando o método.createDataFrame()do Spark compd_tempcomo argumento. - Examine a lista de tabelas de seu cluster do Spark e verifique se o novo DataFrame não está presente. Lembre-se de que você pode usar
spark.catalog.listTables()para fazer isso. - Registre o
spark_tempDataFrame que você acabou de criar como uma tabela temporária usando o.createOrReplaceTempView()método. A tabela temporária deve ser nomeada"temp". Lembre-se de que o nome da tabela é definido incluindo-o como único argumento do seu método! - Examine a lista de tabelas novamente.
exercicio interativo prático
Tente este exercicio completando este código de exemplo.
# Create pd_temp
pd_temp = pd.DataFrame(np.random.random(10))
# Create spark_temp from pd_temp
spark_temp = ____
# Examine the tables in the catalog
print(____)
# Add spark_temp to the catalog
spark_temp.____
# Examine the tables in the catalog again
print(____)