Cache inspecteren in de Spark UI
Er is een dataframe partitioned_df beschikbaar. Dit wordt gebruikt om een tijdelijke tabel text te registreren. text wordt vervolgens gecachet met spark.catalog.cacheTable('text'). Als je Spark lokaal zou draaien, is de Spark UI beschikbaar op http://localhost:4040/storage/. Bekijk voor deze oefening de volgende afbeelding. Deze laat zien wat de Spark UI toont zodra de cache voor text is geladen:
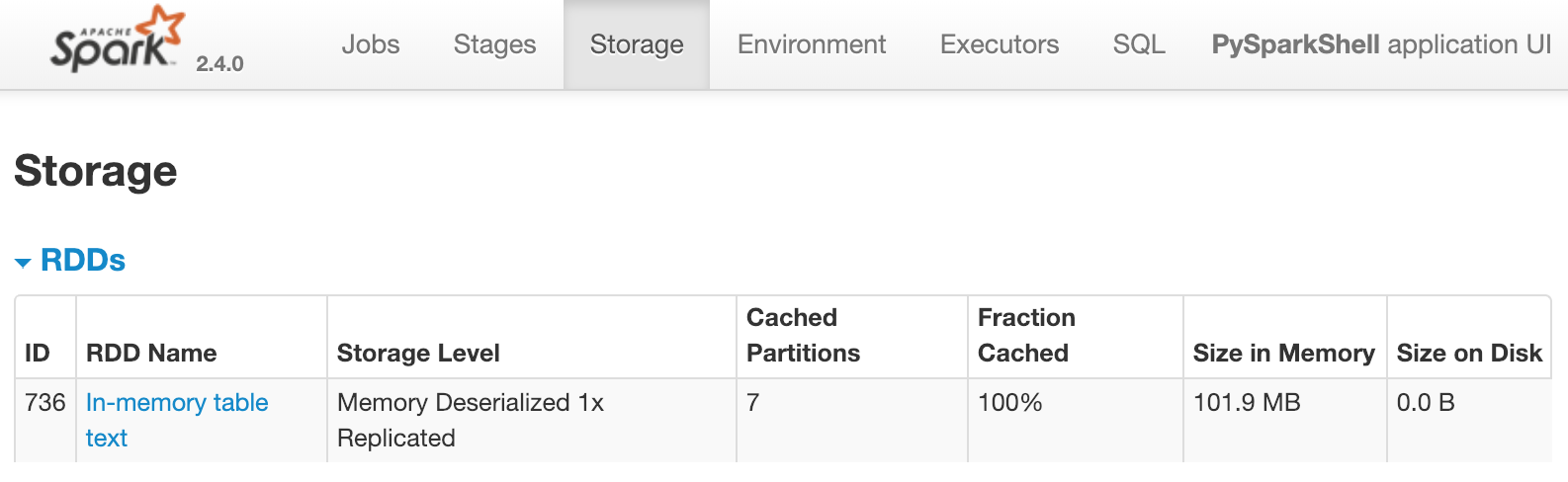
Hieruit blijkt dat een tabel text met zeven partities in het geheugen is gecachet. Welke van de volgende opties zorgt er direct voor dat het bovenstaande in de Spark UI verschijnt?
Een transformatie uitvoeren op het onderliggende dataframe, bijvoorbeeld
df = partitioned_df.distinct().Het onderliggende dataframe tellen, bijvoorbeeld:
partitioned_df.count()De tabel query’en met bijvoorbeeld:
spark.sql("select count(*) from text")De query uitvoeren en het resultaat tonen, bijvoorbeeld:
spark.sql("select count(*) from text").show()
Deze oefening maakt deel uit van de cursus
Introductie tot Spark SQL in Python
Interactieve oefening met praktijkervaring
Zet theorie om in actie met een van onze interactieve oefeningen
 Begin oefening
Begin oefening