La funzione obiettivo surrogata con clipping
Implementa la funzione calculate_loss() per PPO. Questo richiede di codificare l'innovazione chiave di PPO: la funzione di loss surrogata con clipping. Serve a limitare l'aggiornamento della policy per evitare che si allontani troppo dalla policy precedente a ogni passo.
La formula per l'obiettivo surrogato con clipping è
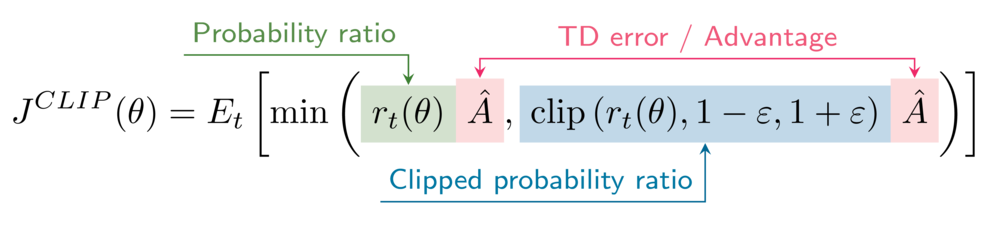
Nel tuo environment, l'hyperparameter di clipping epsilon è impostato a 0.2.
Questo esercizio fa parte del corso
Deep Reinforcement Learning in Python
Istruzioni dell'esercizio
- Ottieni i rapporti di probabilità tra
\pi_\thetae\pi_{\theta_{old}}(versioni non troncata e troncata). - Calcola gli obiettivi surrogati (versioni non troncata e troncata).
- Calcola l'obiettivo surrogato con clipping di PPO.
- Calcola la loss dell'actor.
esercizio interattivo pratico
Prova questo esercizio completando questo codice di esempio.
def calculate_losses(critic_network, action_log_prob, action_log_prob_old,
reward, state, next_state, done):
value = critic_network(state)
next_value = critic_network(next_state)
td_target = (reward + gamma * next_value * (1-done))
td_error = td_target - value
# Obtain the probability ratios
____, ____ = calculate_ratios(action_log_prob, action_log_prob_old, epsilon=.2)
# Calculate the surrogate objectives
surr1 = ratio * ____.____()
surr2 = clipped_ratio * ____.____()
# Calculate the clipped surrogate objective
objective = torch.min(____, ____)
# Calculate the actor loss
actor_loss = ____
critic_loss = td_error ** 2
return actor_loss, critic_loss
actor_loss, critic_loss = calculate_losses(critic_network, action_log_prob, action_log_prob_old,
reward, state, next_state, done)
print(actor_loss, critic_loss)