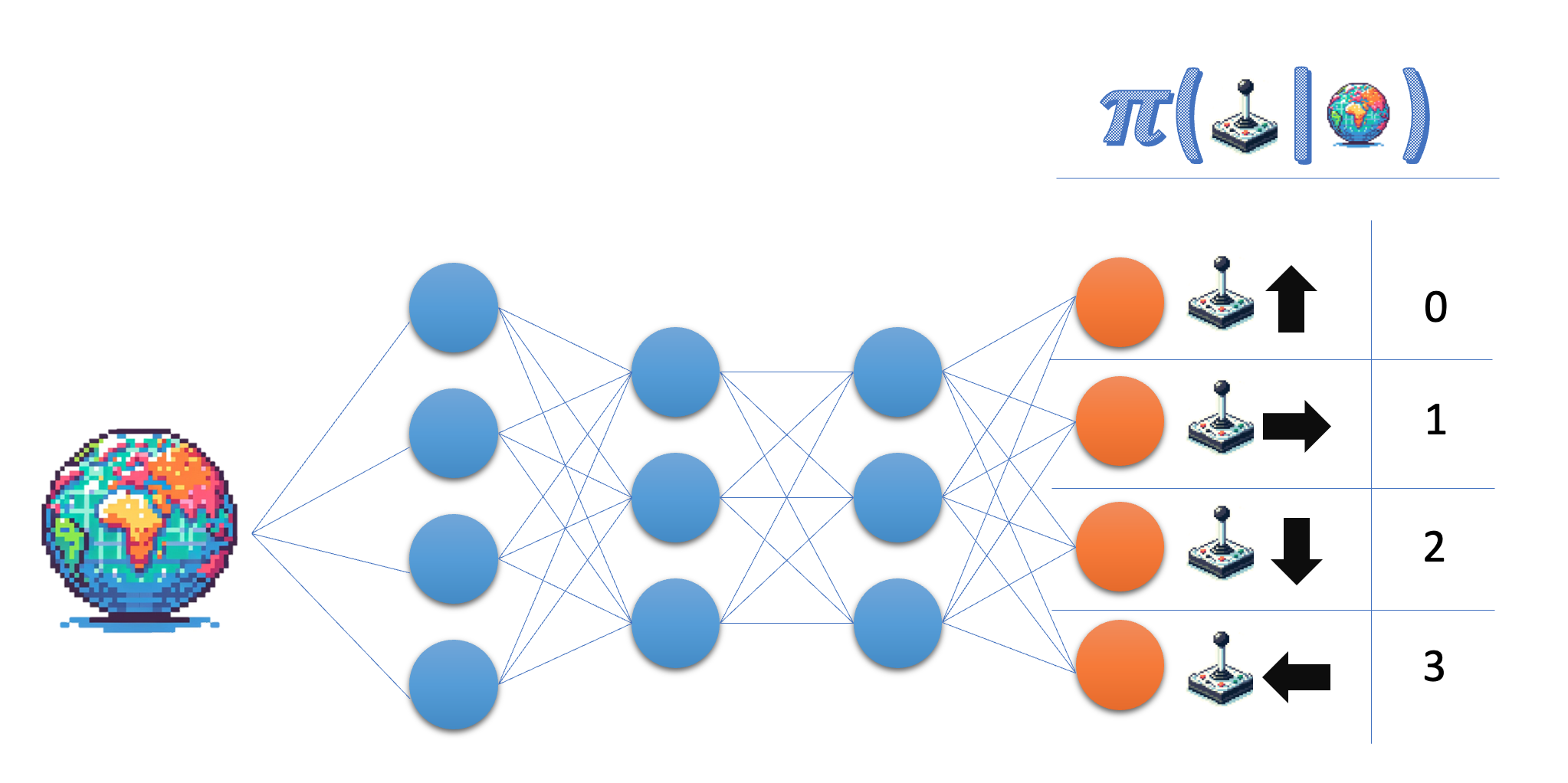
L'architettura della rete di policy
Progetta l'architettura di una Policy Network che potrai usare in seguito per addestrare il tuo agente con policy gradient.
La rete di policy riceve lo stato in input e restituisce una distribuzione di probabilità nello spazio delle azioni. Nell'ambiente Lunar Lander, lavori con quattro azioni discrete, quindi vuoi che la rete restituisca una probabilità per ciascuna di queste azioni.
Questo esercizio fa parte del corso
Deep Reinforcement Learning in Python
Istruzioni dell'esercizio
- Indica la dimensione del layer di output della rete di policy; per flessibilità, usa il nome della variabile invece del numero effettivo.
- Assicurati che il layer finale restituisca probabilità.
esercizio interattivo pratico
Prova questo esercizio completando questo codice di esempio.
class PolicyNetwork(nn.Module):
def __init__(self, state_size, action_size):
super(PolicyNetwork, self).__init__()
self.fc1 = nn.Linear(state_size, 64)
self.fc2 = nn.Linear(64, 64)
# Give the desired size for the output layer
self.fc3 = nn.Linear(64, ____)
def forward(self, state):
x = torch.relu(self.fc1(torch.tensor(state)))
x = torch.relu(self.fc2(x))
# Obtain the action probabilities
action_probs = ____(self.fc3(x), dim=-1)
return action_probs
policy_network = PolicyNetwork(8, 4)
action_probs = policy_network(state)
print('Action probabilities:', action_probs)