Fungsi objektif surrogate terpangkas (clipped)
Implementasikan fungsi calculate_loss() untuk PPO. Ini memerlukan pengodean inovasi kunci PPO — fungsi loss surrogate yang dipangkas (clipped). Pendekatan ini membantu membatasi pembaruan kebijakan agar tidak bergeser terlalu jauh dari kebijakan sebelumnya pada setiap langkah.
Rumus untuk objektif surrogate yang dipangkas adalah
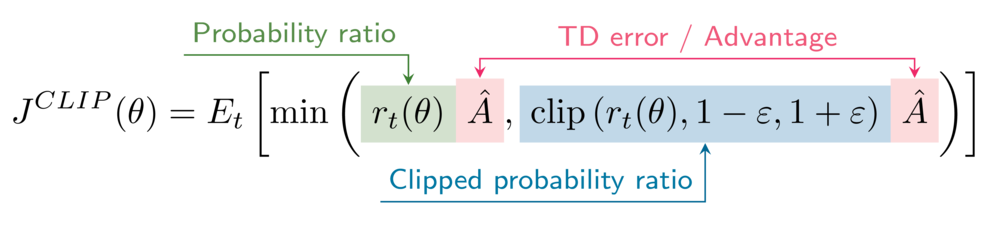
Lingkungan Anda memiliki hiperparameter clipping epsilon yang disetel ke 0.2.
Latihan ini merupakan bagian dari kursus
Deep Reinforcement Learning dengan Python
Instruksi latihan
- Peroleh rasio probabilitas antara
\pi_\thetadan\pi_{\theta_{old}}(versi belum dipangkas dan dipangkas). - Hitung tujuan surrogate (versi belum dipangkas dan dipangkas).
- Hitung objektif surrogate PPO yang dipangkas (clipped).
- Hitung loss aktor.
Latihan interaktif langsung praktik
Cobalah latihan ini dengan melengkapi kode contoh ini.
def calculate_losses(critic_network, action_log_prob, action_log_prob_old,
reward, state, next_state, done):
value = critic_network(state)
next_value = critic_network(next_state)
td_target = (reward + gamma * next_value * (1-done))
td_error = td_target - value
# Obtain the probability ratios
____, ____ = calculate_ratios(action_log_prob, action_log_prob_old, epsilon=.2)
# Calculate the surrogate objectives
surr1 = ratio * ____.____()
surr2 = clipped_ratio * ____.____()
# Calculate the clipped surrogate objective
objective = torch.min(____, ____)
# Calculate the actor loss
actor_loss = ____
critic_loss = td_error ** 2
return actor_loss, critic_loss
actor_loss, critic_loss = calculate_losses(critic_network, action_log_prob, action_log_prob_old,
reward, state, next_state, done)
print(actor_loss, critic_loss)