Arsitektur policy network
Bangun arsitektur Policy Network yang nantinya dapat Anda gunakan untuk melatih agen policy gradient.
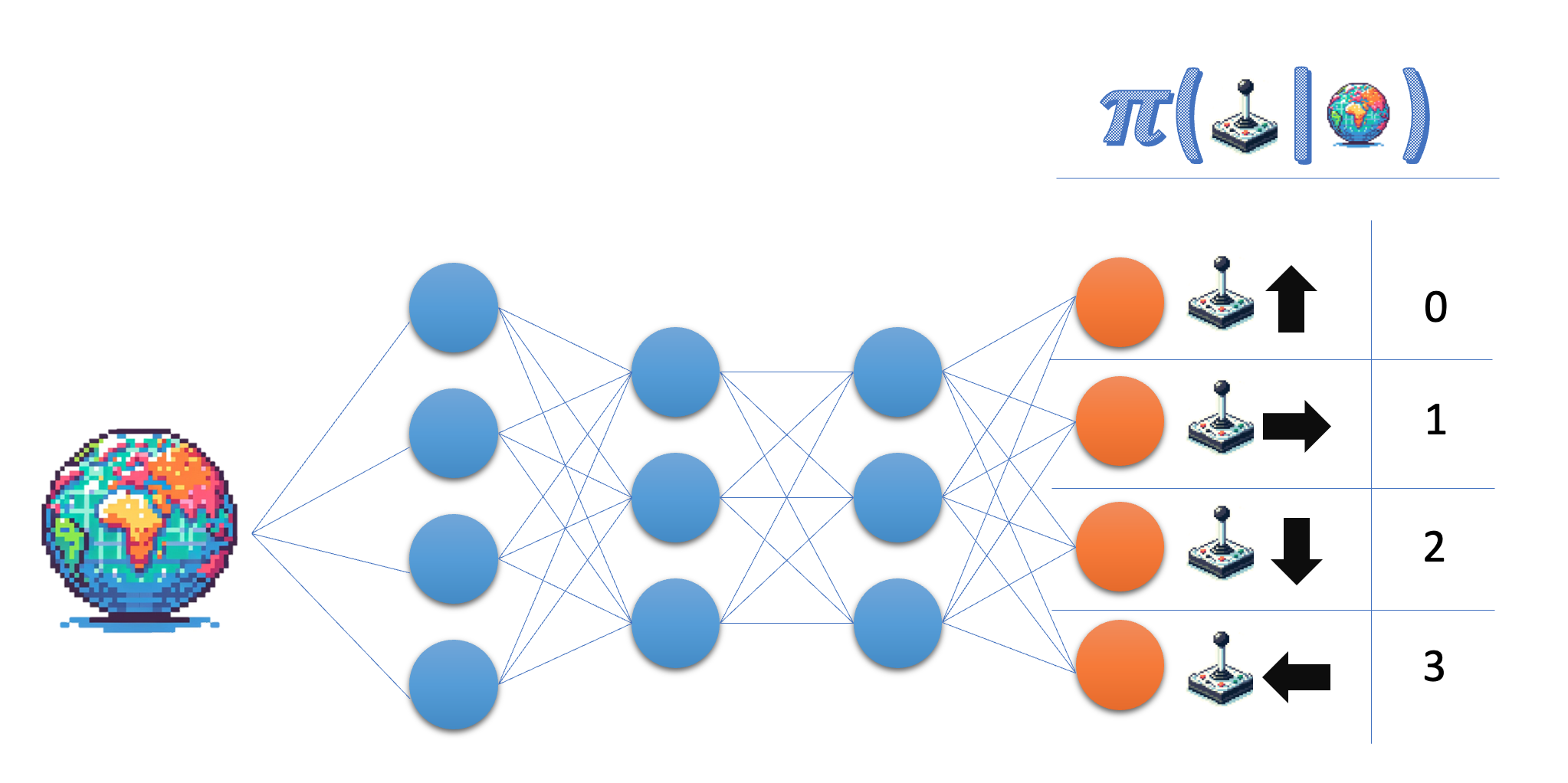
Policy network menerima state sebagai masukan, lalu menghasilkan probabilitas pada ruang aksi. Untuk lingkungan Lunar Lander, Anda bekerja dengan empat aksi diskret, sehingga Anda menginginkan jaringan menghasilkan probabilitas untuk masing-masing aksi tersebut.
Latihan ini merupakan bagian dari kursus
Deep Reinforcement Learning dengan Python
Instruksi latihan
- Tentukan ukuran untuk lapisan keluaran policy network; untuk fleksibilitas, gunakan nama variabel alih-alih angka sebenarnya.
- Pastikan lapisan terakhir mengembalikan probabilitas.
Latihan interaktif langsung praktik
Cobalah latihan ini dengan melengkapi kode contoh ini.
class PolicyNetwork(nn.Module):
def __init__(self, state_size, action_size):
super(PolicyNetwork, self).__init__()
self.fc1 = nn.Linear(state_size, 64)
self.fc2 = nn.Linear(64, 64)
# Give the desired size for the output layer
self.fc3 = nn.Linear(64, ____)
def forward(self, state):
x = torch.relu(self.fc1(torch.tensor(state)))
x = torch.relu(self.fc2(x))
# Obtain the action probabilities
action_probs = ____(self.fc3(x), dim=-1)
return action_probs
policy_network = PolicyNetwork(8, 4)
action_probs = policy_network(state)
print('Action probabilities:', action_probs)