Lettres du code génétique
Les éléments de base de l’ARN sont quatre molécules désignées chacune par une seule lettre : adénine (A), cytosine (C), guanine (G) et uracile (U). L’information portée par un brin d’ARN peut être représentée comme une longue séquence de ces quatre lettres. Pour lire ce code, il faut diviser cette chaîne en séquences de trois lettres chacune (par exemple GCU, ACG, …). Ces séquences de trois lettres sont appelées des codons. Le concept est illustré dans l’image ci‑dessous.
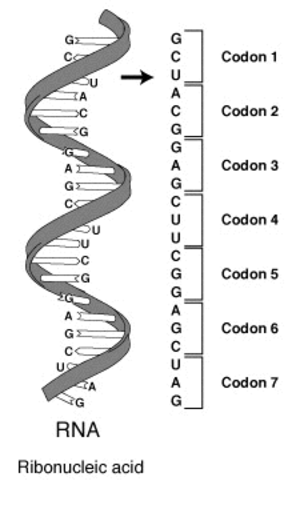
Votre objectif dans cet exercice est de créer un data frame contenant toutes les séquences possibles de trois lettres (codons) à partir d’un vecteur composé des quatre lettres représentant les briques de l’ARN.
Cet exercice fait partie du cours
<cours>Reshaper des données avec tidyr</cours>Exercice interactif pratique
Essayez cet exercice en complétant ce code d’exemple.
letters <- c("A", "C", "G", "U")
# Create a tibble with all possible 3 way combinations
codon_df <- ___
codon_df