Pon algo de Spark en tus datos
En el último ejercicio, viste cómo mover datos de Spark a pandas. Sin embargo, ¡quizás quieras ir en la otra dirección, y poner un pandas DataFrame en un clúster de Spark! La clase SparkSession también tiene un método para esto.
El método .createDataFrame() toma un pandas DataFrame y devuelve un Spark DataFrame.
El resultado de este método se almacena localmente, no en el catálogo SparkSession. Esto significa que puedes utilizar todos los métodos de Spark DataFrame en él, pero no puedes acceder a los datos en otros contextos.
Por ejemplo, una consulta SQL (que utilice el.sql()método) que haga referencia a tu DataFrame generará un error. Para acceder a los datos de esta forma, tienes que guardarlos como una tabla temporal.
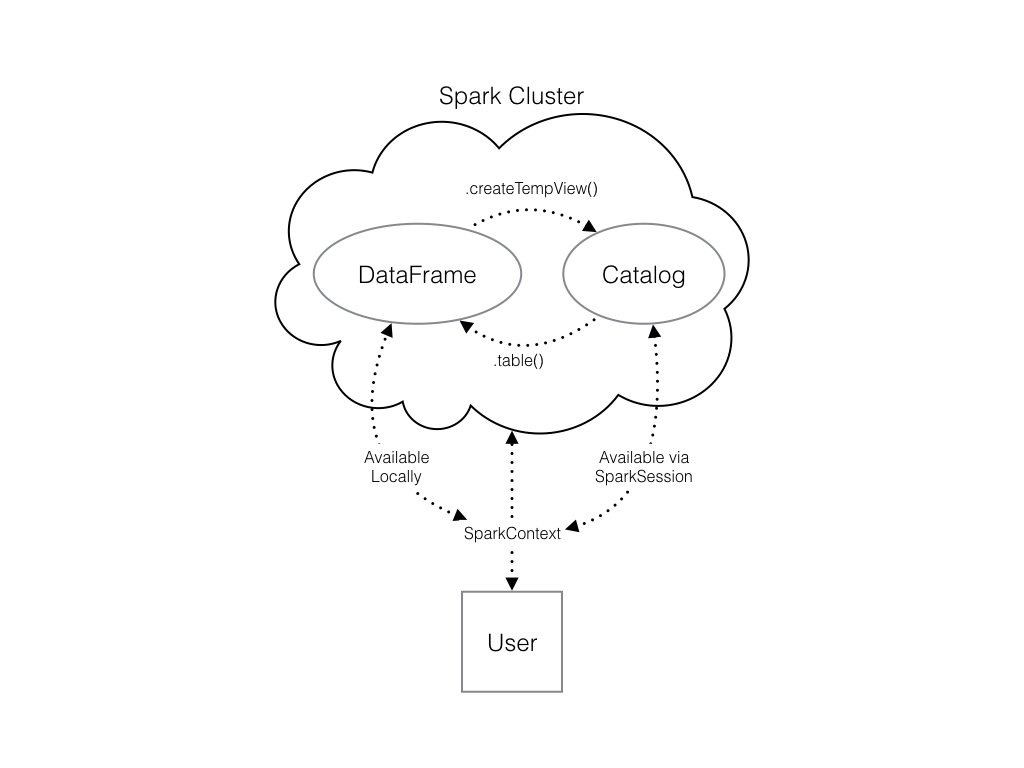
Puedes hacerlo utilizando el método .createTempView() Spark DataFrame, que toma como único argumento el nombre de la tabla temporal que quieres registrar. Este método registra el DataFrame como una tabla en el catálogo, pero como esta tabla es temporal, solo se puede acceder a ella desde el SparkSession específico utilizado para crear el DataFrame de Spark.
También existe el método .createOrReplaceTempView(). Esto crea de forma segura una nueva tabla temporal si antes no había nada, o actualiza una tabla existente si ya había una definida. Utilizarás este método para evitar problemas con las tablas duplicadas.
Echa un vistazo al diagrama para ver las distintas formas en que tus estructuras de datos Spark interactúan entre sí.
Ya hay un SparkSession llamado spark en tu espacio de trabajo, numpy se ha importado como np, y pandas como pd.
Este ejercicio forma parte del curso
Fundamentos de PySpark
Instrucciones del ejercicio
- El código para crear un
pandasDataFrame de números aleatorios ya se ha proporcionado y se ha guardado enpd_temp. - Crea un Spark DataFrame llamado
spark_templlamando al método Spark.createDataFrame()conpd_tempcomo argumento. - Examina la lista de tablas de tu clúster de Spark y comprueba que el nuevo DataFrame no está presente. Recuerda que puedes utilizar
spark.catalog.listTables()para hacerlo. - Registra el
spark_tempDataFrame que acabas de crear como una tabla temporal utilizando el.createOrReplaceTempView()método. La tabla temporal debería llamarse"temp". Recuerda que el nombre de la tabla se establece ¡incluyéndolo como único argumento de tu método! - Examina de nuevo la lista de tablas.
ejercicio interactivo práctico
Prueba este ejercicio completando este código de ejemplo.
# Create pd_temp
pd_temp = pd.DataFrame(np.random.random(10))
# Create spark_temp from pd_temp
spark_temp = ____
# Examine the tables in the catalog
print(____)
# Add spark_temp to the catalog
spark_temp.____
# Examine the tables in the catalog again
print(____)