Pasos de la canalización de datos
Una de tus canalizaciones de datos más críticas para el negocio en Sierra Publishing depende de un flujo de datos de alta velocidad que proviene de un stream de Kafka. Necesitamos leer los datos y unirlos con algunos otros conjuntos de datos.
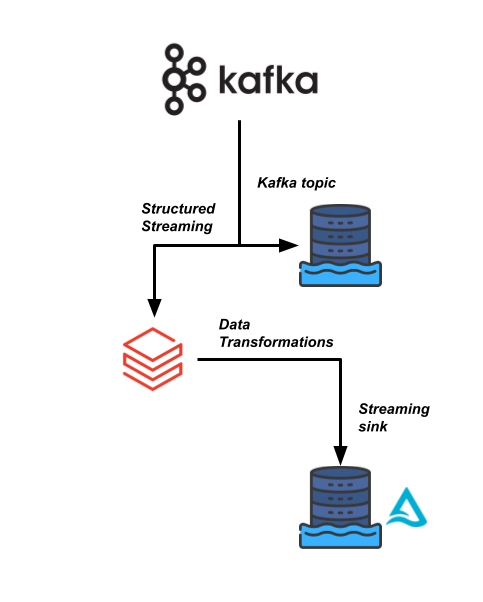
Tu equipo de ingeniería de datos quiere usar Databricks para hacer que esta canalización sea más eficiente y permitir que los consumidores posteriores lean estos datos en tiempo real para sus análisis.
Este ejercicio forma parte del curso
Conceptos de Databricks
ejercicio interactivo práctico
Convierte la teoría en práctica con uno de nuestros ejercicios interactivos
 Empezar ejercicio
Empezar ejercicio