Implementiere die Double-Q-Learning-Aktualisierungsregel
Double Q-learning ist eine Erweiterung des Q-Learning-Algorithmus. Sie reduziert die Überschätzung von Aktionswerten, indem zwei separate Q-Tabellen geführt und aktualisiert werden. Durch das Entkoppeln der Aktionsauswahl von der Aktionsevaluierung liefert Double Q-learning eine genauere Schätzung der Q-Werte. In dieser Übung implementierst du die Double-Q-Learning-Aktualisierungsregel. Eine Liste Q mit zwei Q-Tabellen wurde bereits erzeugt.
Die Bibliothek numpy wurde als np importiert, und die Werte für gamma und alpha wurden vorab geladen. Die Aktualisierungsformeln findest du unten:
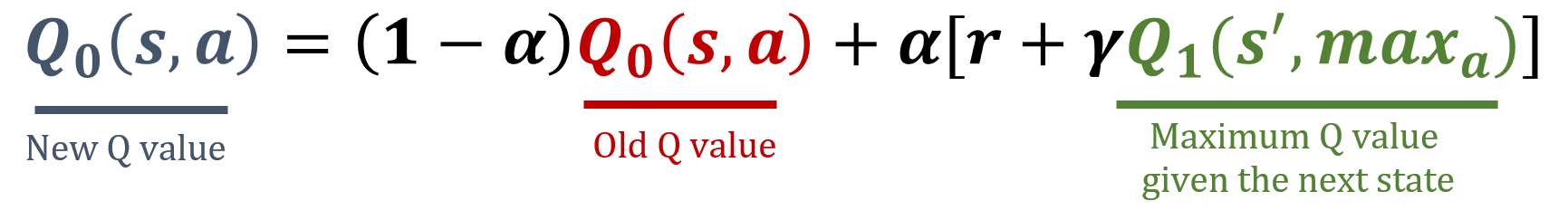
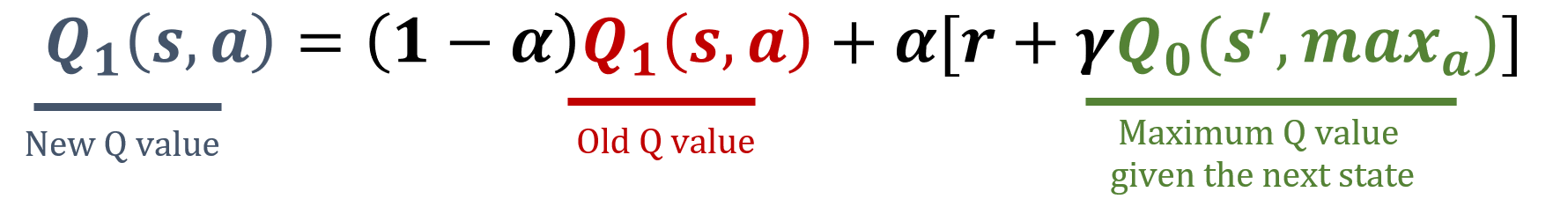
Diese Übung ist Teil des Kurses
<Kurs>Reinforcement Learning mit Gymnasium in Python</Kurs>Übungsanweisungen
- Entscheide zufällig, welche Q-Tabelle innerhalb von
Qfür die Aktionswertschätzung aktualisiert wird, indem du ihren Indexiberechnest. - Führe die nötigen Schritte aus, um
Q[i]zu aktualisieren.
Interaktive praktische Übung
Versuche dich an dieser Übung, indem du diesen Beispielcode vervollständigst.
Q = [np.random.rand(8,4), np.random.rand(8,4)]
def update_q_tables(state, action, reward, next_state):
# Get the index of the table to update
i = ____
# Update Q[i]
best_next_action = ____
Q[i][state, action] = ____