Expected-SARSA-Aktualisierungsregel
In dieser Übung implementierst du die Expected-SARSA-Aktualisierungsregel, einen modellfreien Temporal-Difference-Algorithmus im RL. Expected SARSA schätzt den erwarteten Wert der aktuellen Policy, indem es über alle möglichen Aktionen mittelt, und liefert damit ein stabileres Update-Ziel als SARSA. Die in Expected SARSA verwendeten Formeln findest du unten.
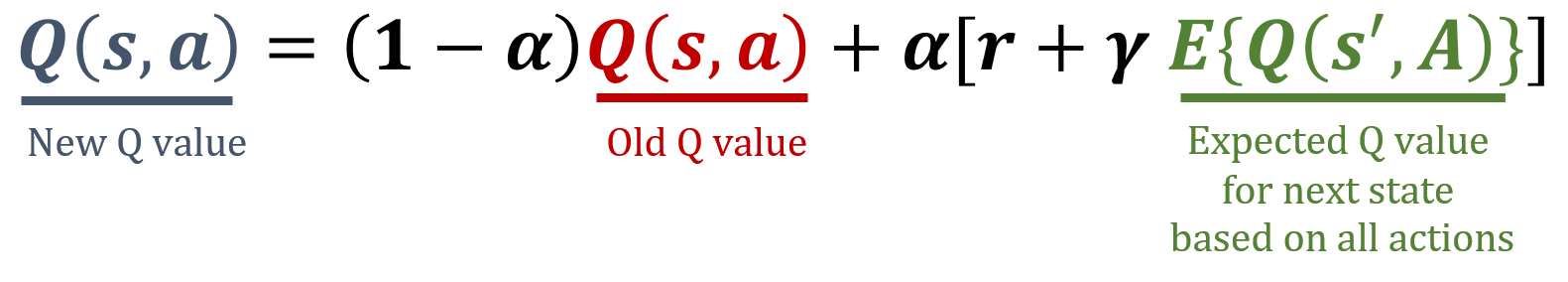
Die Bibliothek numpy wurde als np importiert.
Diese Übung ist Teil des Kurses
<Kurs>Reinforcement Learning mit Gymnasium in Python</Kurs>Übungsanweisungen
- Berechne den erwarteten Q-Wert für den
next_state. - Aktualisiere den Q-Wert für den aktuellen
stateund dieactionmit der Expected-SARSA-Formel. - Aktualisiere die Q-Tabelle
Q, wobei ein Agent in Zustand2die Aktion1wählt, zu Zustand3wechselt und eine Belohnung von5erhält.
Interaktive praktische Übung
Versuche dich an dieser Übung, indem du diesen Beispielcode vervollständigst.
def update_q_table(state, action, next_state, reward):
# Calculate the expected Q-value for the next state
expected_q = ____
# Update the Q-value for the current state and action
Q[state, action] = ____
Q = np.random.rand(5, 2)
print("Old Q:\n", Q)
alpha = 0.1
gamma = 0.99
# Update the Q-table
update_q_table(____, ____, ____, ____)
print("Updated Q:\n", Q)