Die beschnittene Surrogat-Zielfunktion
Implementiere die Funktion calculate_loss() für PPO. Dazu muss die wichtigste Neuerung von PPO kodiert werden - die geclippte Surrogatverlustfunktion. Sie hilft, die Aktualisierung der Richtlinie einzuschränken, damit sie sich nicht bei jedem Schritt zu weit von der vorherigen Richtlinie entfernt.
Die Formel für das beschnittene Surrogatziel lautet
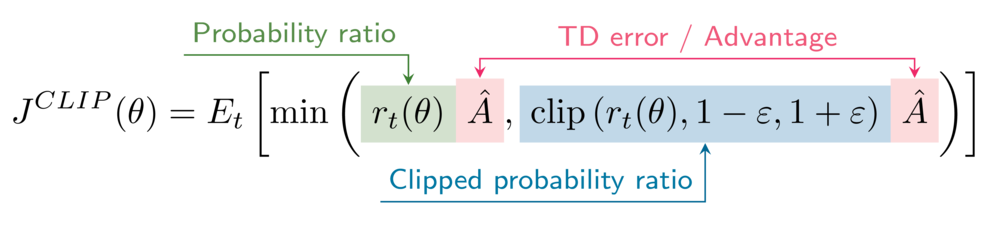
In deiner Umgebung ist der Clipping-Hyperparameter epsilon auf 0,2 gesetzt.
Diese Übung ist Teil des Kurses
<Kurs>Deep Reinforcement Learning in Python</Kurs>Übungsanweisungen
- Ermittle die Wahrscheinlichkeitsverhältnisse zwischen
\pi_\thetaund\pi_{\theta_{old}}(unbeschnittene und beschnittene Version). - Berechne die Ersatzziele (nicht beschnittene und beschnittene Versionen).
- Berechne das PPO beschnittene Surrogatziel.
- Berechne den Verlust des Akteurs.
Interaktive praktische Übung
Versuche dich an dieser Übung, indem du diesen Beispielcode vervollständigst.
def calculate_losses(critic_network, action_log_prob, action_log_prob_old,
reward, state, next_state, done):
value = critic_network(state)
next_value = critic_network(next_state)
td_target = (reward + gamma * next_value * (1-done))
td_error = td_target - value
# Obtain the probability ratios
____, ____ = calculate_ratios(action_log_prob, action_log_prob_old, epsilon=.2)
# Calculate the surrogate objectives
surr1 = ratio * ____.____()
surr2 = clipped_ratio * ____.____()
# Calculate the clipped surrogate objective
objective = torch.min(____, ____)
# Calculate the actor loss
actor_loss = ____
critic_loss = td_error ** 2
return actor_loss, critic_loss
actor_loss, critic_loss = calculate_losses(critic_network, action_log_prob, action_log_prob_old,
reward, state, next_state, done)
print(actor_loss, critic_loss)