Die Architektur des Politiknetzwerks
Baue die Architektur für ein Policy-Netzwerk auf, das du später zum Trainieren deines Policy-Gradienten-Agenten verwenden kannst.
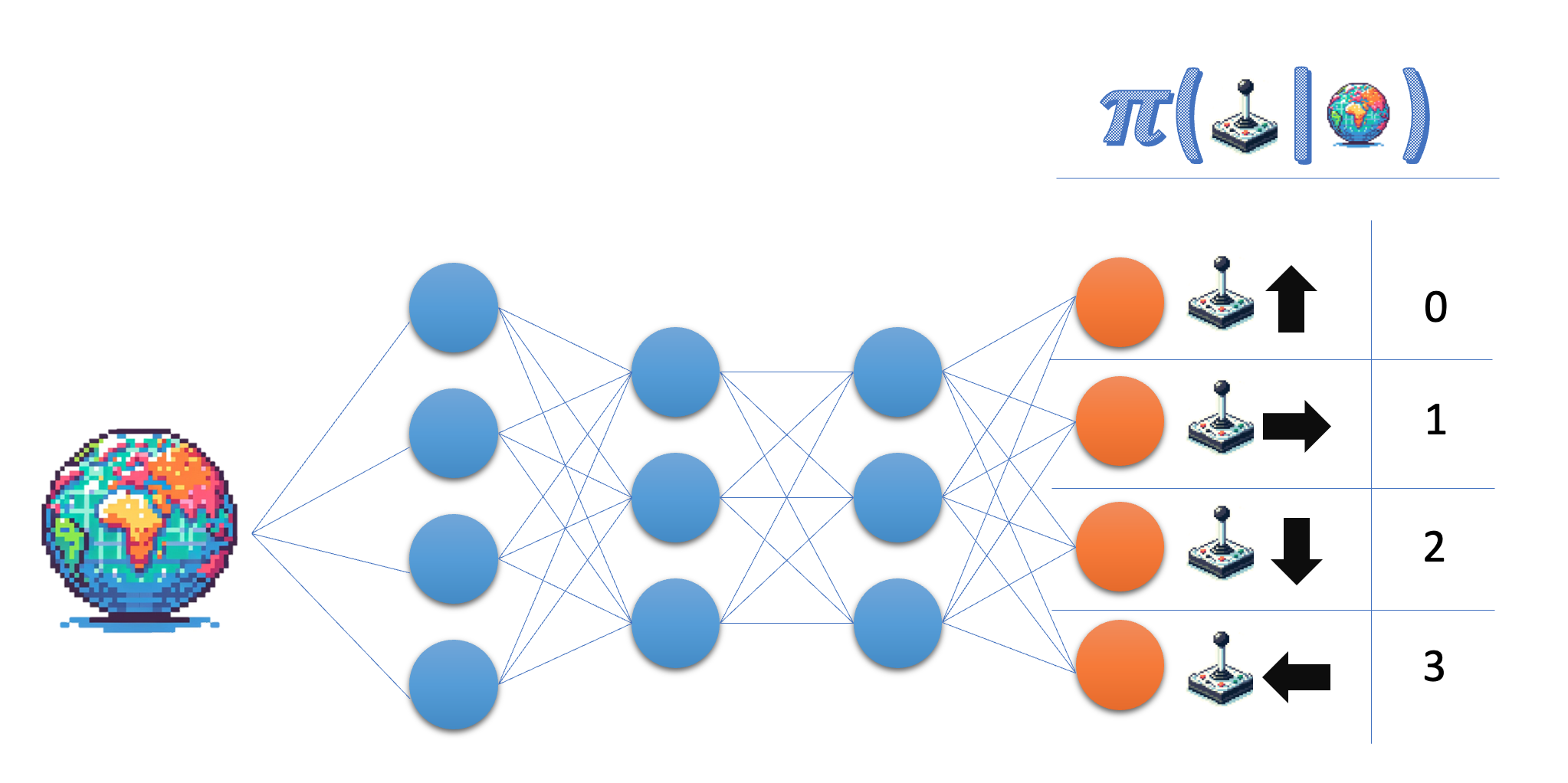
Das Policy-Netzwerk nimmt den Zustand als Eingabe und gibt eine Wahrscheinlichkeit im Aktionsraum aus. Für die Lunar Lander-Umgebung arbeitest du mit vier diskreten Aktionen, also soll dein Netz für jede dieser Aktionen eine Wahrscheinlichkeit ausgeben.
Diese Übung ist Teil des Kurses
<Kurs>Deep Reinforcement Learning in Python</Kurs>Übungsanweisungen
- Gib die Größe der Ausgabeschicht des Policy-Netzes an. Um flexibel zu sein, verwende den Variablennamen und nicht die tatsächliche Zahl.
- Stelle sicher, dass die letzte Ebene Wahrscheinlichkeiten liefert.
Interaktive praktische Übung
Versuche dich an dieser Übung, indem du diesen Beispielcode vervollständigst.
class PolicyNetwork(nn.Module):
def __init__(self, state_size, action_size):
super(PolicyNetwork, self).__init__()
self.fc1 = nn.Linear(state_size, 64)
self.fc2 = nn.Linear(64, 64)
# Give the desired size for the output layer
self.fc3 = nn.Linear(64, ____)
def forward(self, state):
x = torch.relu(self.fc1(torch.tensor(state)))
x = torch.relu(self.fc2(x))
# Obtain the action probabilities
action_probs = ____(self.fc3(x), dim=-1)
return action_probs
policy_network = PolicyNetwork(8, 4)
action_probs = policy_network(state)
print('Action probabilities:', action_probs)