Trénování modelu s word embeddings
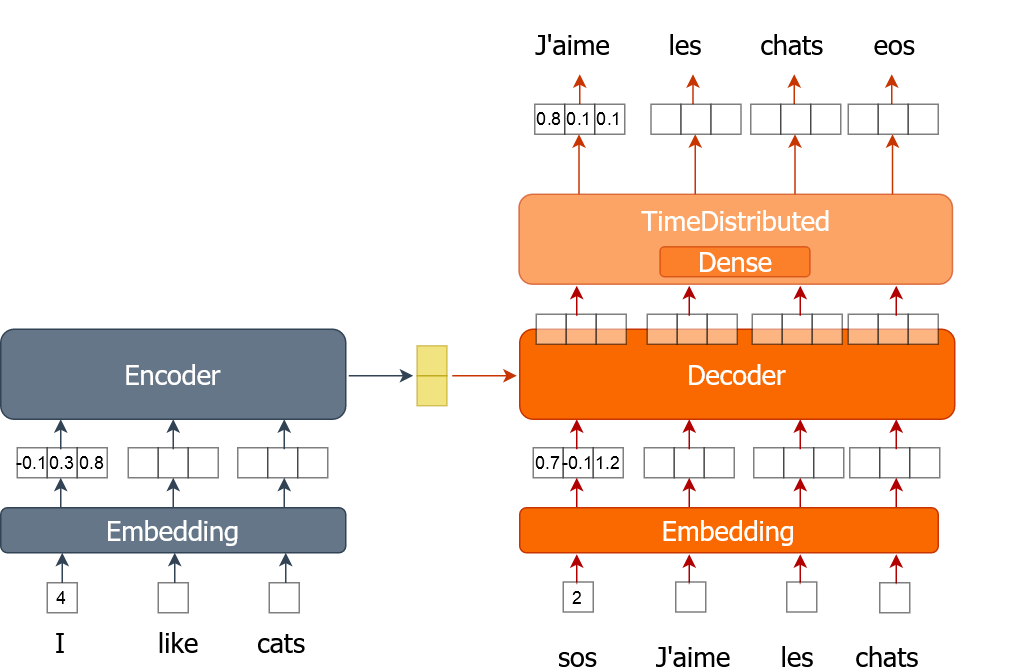
V této lekci se naučíš, jak implementovat trénování překladového modelu, který využívá word embeddings. Každé slovo je reprezentováno jediným číslem místo one-hot enkódovaného vektoru, jak tomu bylo v předchozích cvičeních. Model budeš trénovat po více epochách a procházet celou datovou sadou po dávkách.
Pro toto cvičení máš k dispozici trénovací data (tr_en a tr_fr) ve formě seznamu vět. Použiješ jen velmi malý vzorek (1 000 vět) ze skutečných dat, protože jinak by trénování trvalo velmi dlouho. Máš také k dispozici funkci sents2seqs() a model nmt_emb, který jsi implementoval/a v předchozím cvičení. Pamatuj, že en_x označuje vstupy enkodéru a de_x vstupy dekodéru.
Toto cvičení je součástí kurzu
Machine Translation with Keras
Pokyny k cvičení
- Pomocí funkce
sents2seqs()získej jednu dávku francouzských vět bez one-hot enkódování. - Z pole
de_xyvezmi všechna slova kromě posledního. - Z pole
de_xy_oh(francouzská slova s one-hot enkódováním) vezmi všechna slova kromě prvního. - Natrénuj model na jedné dávce dat.
Interaktivní cvičení na vyzkoušení si v praxi
Vyzkoušejte si toto cvičení dokončením tohoto ukázkového kódu.
for ei in range(3):
for i in range(0, train_size, bsize):
en_x = sents2seqs('source', tr_en[i:i+bsize], onehot=False, reverse=True)
# Get a single batch of French sentences with no onehot encoding
de_xy = ____('target', ____[i:i+bsize], ____=____)
# Get all words except the last word in that batch
de_x = de_xy[:,____]
de_xy_oh = sents2seqs('target', tr_fr[i:i+bsize], onehot=True)
# Get all words except the first from de_xy_oh
de_y = de_xy_oh[____,____,____]
# Training the model on a single batch of data
nmt_emb.train_on_batch([____,____], ____)
res = nmt_emb.evaluate([en_x, de_x], de_y, batch_size=bsize, verbose=0)
print("{} => Loss:{}, Train Acc: {}".format(ei+1,res[0], res[1]*100.0))