Double Q-learning güncelleme kuralını uygulama
Double Q-learning, eylem değerlerinin aşırı tahmin edilmesini azaltmak için iki ayrı Q-tablosu tutup güncelleyen Q-learning algoritmasının bir uzantısıdır. Eylem seçimi ile eylem değerlendirmesini birbirinden ayırarak, Double Q-learning Q-değerlerinin daha isabetli tahmin edilmesini sağlar. Bu egzersizde Double Q-learning güncelleme kuralını uygulayacaksın. İki Q-tablosu içeren bir Q listesi oluşturuldu.
numpy kütüphanesi np olarak içe aktarıldı ve gamma ile alpha değerleri önceden yüklendi. Güncelleme formülleri aşağıdadır:
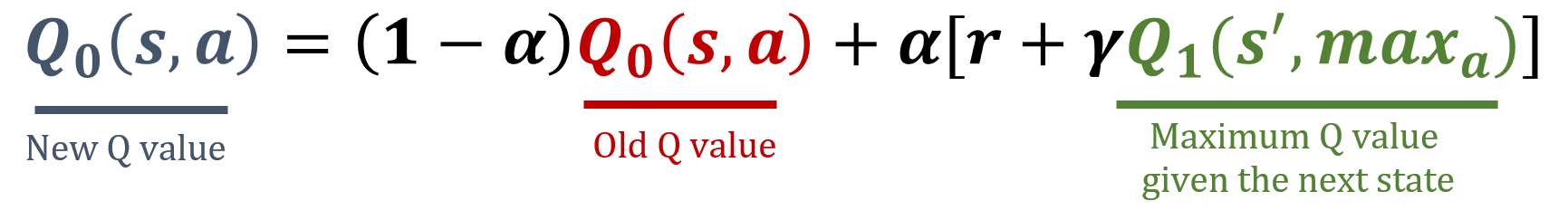
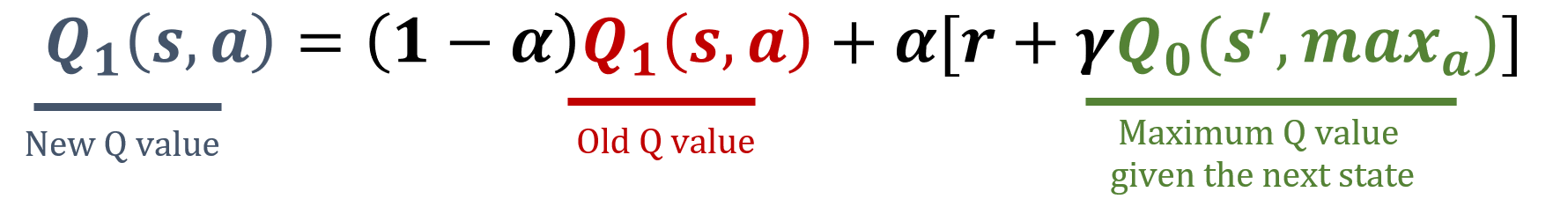
Bu egzersiz, kursun bir parçasıdır
Python ile Gymnasium'da Reinforcement Learning
Egzersiz talimatları
- Eylem değeri tahmini için
Qiçindeki hangi Q-tablosunun güncelleneceğine rastgele karar verip indeksiniiolarak hesapla. Q[i]güncellemesi için gerekli adımları uygula.
Uygulamalı etkileşimli egzersiz
Bu egzersizi bu örnek kodu tamamlayarak deneyin.
Q = [np.random.rand(8,4), np.random.rand(8,4)]
def update_q_tables(state, action, reward, next_state):
# Get the index of the table to update
i = ____
# Update Q[i]
best_next_action = ____
Q[i][state, action] = ____