Expected SARSA güncelleme kuralı
Bu egzersizde, zaman farkı temelli modelden bağımsız bir RL algoritması olan Expected SARSA güncelleme kuralını uygulayacaksın. Expected SARSA, tüm olası eylemler üzerinde ortalama alarak geçerli politikanın beklenen değerini tahmin eder; bu da SARSA'ya kıyasla daha kararlı bir güncelleme hedefi sağlar. Expected SARSA'da kullanılan formülleri aşağıda bulabilirsin.
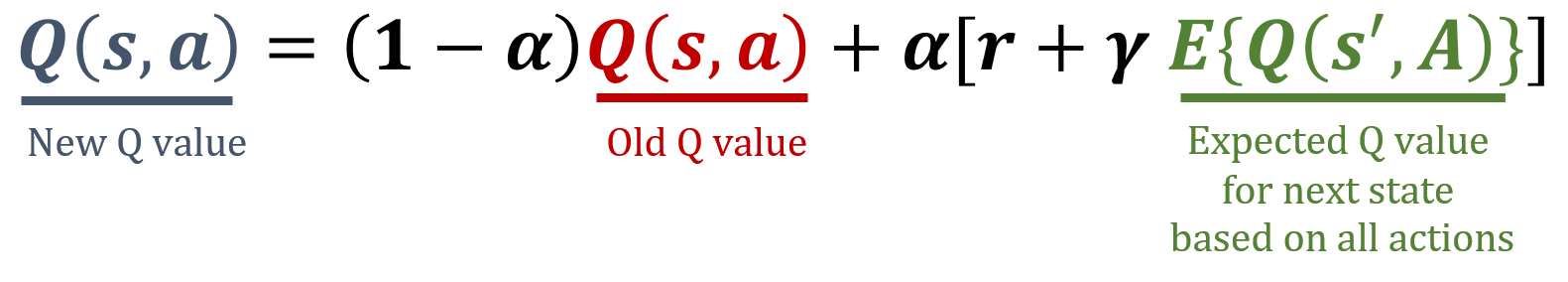
numpy kütüphanesi np olarak içe aktarıldı.
Bu egzersiz, kursun bir parçasıdır
Python ile Gymnasium'da Reinforcement Learning
Egzersiz talimatları
next_stateiçin beklenen Q-değerini hesapla.- Expected SARSA formülünü kullanarak mevcut
stateveactioniçin Q-değerini güncelle. - Bir ajanın durum
2'de eylem1aldığını, durum3'e geçtiğini ve5ödül aldığını varsayarak Q-tablosuQ'yu güncelle.
Uygulamalı etkileşimli egzersiz
Bu egzersizi bu örnek kodu tamamlayarak deneyin.
def update_q_table(state, action, next_state, reward):
# Calculate the expected Q-value for the next state
expected_q = ____
# Update the Q-value for the current state and action
Q[state, action] = ____
Q = np.random.rand(5, 2)
print("Old Q:\n", Q)
alpha = 0.1
gamma = 0.99
# Update the Q-table
update_q_table(____, ____, ____, ____)
print("Updated Q:\n", Q)