Kelime gömme tabanlı modeli eğitme
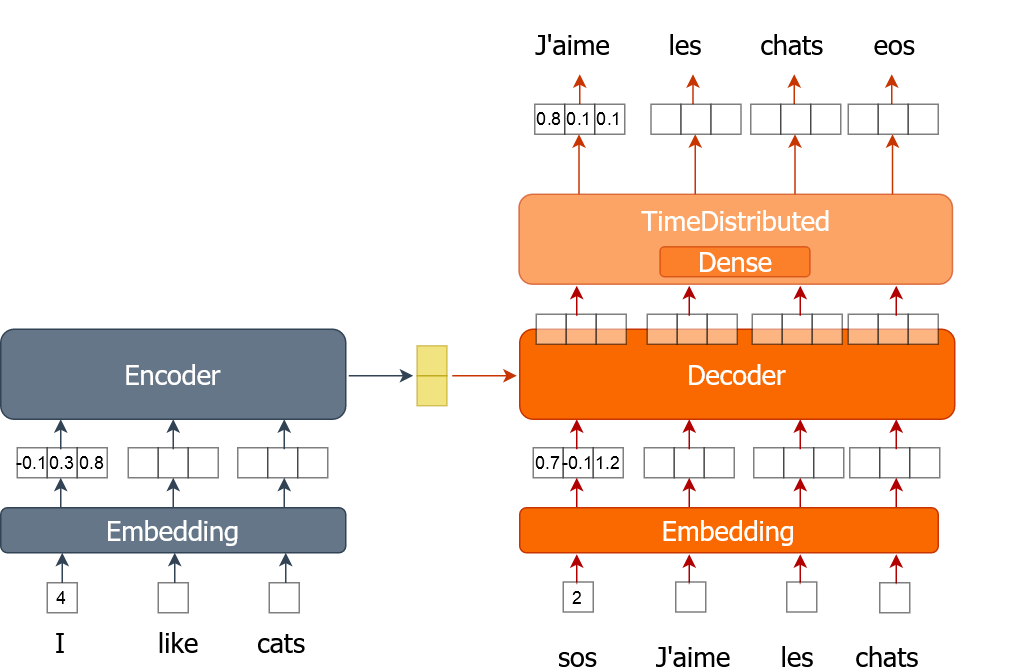
Burada, kelime gömmeleri kullanan bir makine çevirmeni modelinin eğitim sürecini nasıl uygulayacağını öğreneceksin. Bir kelime, önceki egzersizlerde yaptığın gibi tek-sıcak (one-hot) kodlu bir vektör yerine tek bir sayı olarak temsil edilir. Modeli, tam veri kümesi üzerinde mini yığınlar (batch) halinde dolaşırken birden çok epoch boyunca eğiteceksin.
Bu egzersiz için sana, birer cümle listesi biçiminde eğitim verileri (tr_en ve tr_fr) veriliyor. Eğitim uzun sürebileceği için gerçek verinin yalnızca çok küçük bir örneğini (1000 cümle) kullanacaksın. Ayrıca önceki egzersizde uyguladığın sents2seqs() fonksiyonu ve nmt_emb modeli de elinde. Kodda en_x kodlayıcı (encoder) girdilerini, de_x ise kod çözücü (decoder) girdilerini ifade eder; bunu unutma.
Bu egzersiz, kursun bir parçasıdır
Keras ile Machine Translation
Egzersiz talimatları
sents2seqs()fonksiyonunu kullanarak one-hot kodlama olmadan tek bir Fransızca cümle yığınını al.de_xyiçinden son kelime hariç tüm kelimeleri al.de_xy_oh(one-hot kodlu Fransızca kelimeler) içinden ilk kelime hariç tüm kelimeleri al.- Modeli tek bir veri yığınıyla eğit
Uygulamalı etkileşimli egzersiz
Bu egzersizi bu örnek kodu tamamlayarak deneyin.
for ei in range(3):
for i in range(0, train_size, bsize):
en_x = sents2seqs('source', tr_en[i:i+bsize], onehot=False, reverse=True)
# Get a single batch of French sentences with no onehot encoding
de_xy = ____('target', ____[i:i+bsize], ____=____)
# Get all words except the last word in that batch
de_x = de_xy[:,____]
de_xy_oh = sents2seqs('target', tr_fr[i:i+bsize], onehot=True)
# Get all words except the first from de_xy_oh
de_y = de_xy_oh[____,____,____]
# Training the model on a single batch of data
nmt_emb.train_on_batch([____,____], ____)
res = nmt_emb.evaluate([en_x, de_x], de_y, batch_size=bsize, verbose=0)
print("{} => Loss:{}, Train Acc: {}".format(ei+1,res[0], res[1]*100.0))