Sentimento da comunidade sobre scooters
A Câmara Municipal quer entender como diferentes comunidades da cidade estão reagindo aos scooters. O conjunto de dados cresceu desde a análise inicial da Sam e agora contém relatos em vietnamita, tagalo, espanhol e inglês.
Eles pedem para Sam investigar. Ela decide que a melhor forma de representar uma comunidade é pelo idioma (pelo menos com os dados a que tem acesso agora).
Ela já carregou o CSV na variável scooter_df:
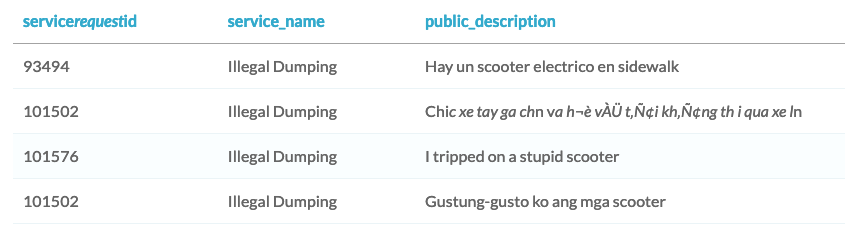
Neste exercício, você vai ajudar a Sam a entender o sentimento em vários idiomas. Isso vai ajudar a cidade a compreender como diferentes comunidades estão se relacionando com os scooters, algo que pode influenciar os votos dos membros da Câmara Municipal.
Este exercicio faz parte do curso
Introdução ao AWS Boto em Python
Instruções do exercicio
- Para cada linha do DataFrame, detecte o idioma dominante.
- Use o idioma detectado para determinar o sentimento da descrição.
- Agrupe o DataFrame pelas colunas
'sentiment'e'lang', nessa ordem.
exercicio interativo prático
Tente este exercicio completando este código de exemplo.
for index, row in scooter_requests.iterrows():
# For every DataFrame row
desc = scooter_requests.loc[index, 'public_description']
if desc != '':
# Detect the dominant language
resp = comprehend.____(____=desc)
lang_code = resp['Languages'][0]['LanguageCode']
scooter_requests.loc[index, 'lang'] = lang_code
# Use the detected language to determine sentiment
scooter_requests.loc[index, 'sentiment'] = comprehend.____(
____=desc,
____=lang_code)['____']
# Perform a count of sentiment by group.
counts = scooter_requests.groupby(['sentiment', 'lang']).count()
counts.head()