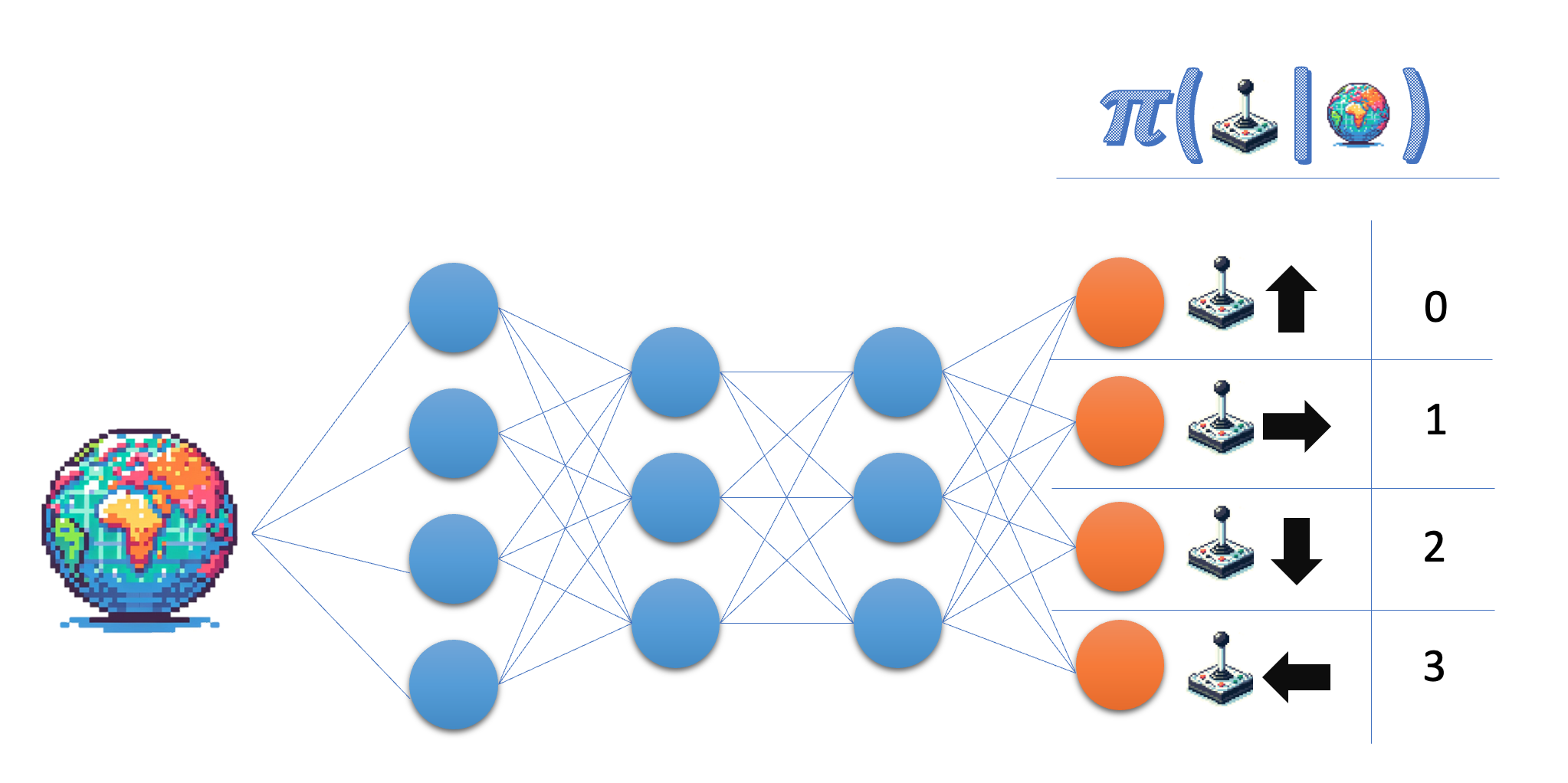
A arquitetura da rede de políticas
Crie a arquitetura de uma rede de políticas que você poderá usar posteriormente para treinar seu agente de gradiente de políticas.
A rede de políticas recebe o estado como entrada e gera uma probabilidade no espaço de ação. Para o ambiente do Lunar Lander, você trabalha com quatro ações discretas e, portanto, deseja que sua rede produza uma probabilidade para cada uma dessas ações.
Este exercicio faz parte do curso
Aprendizado por reforço profundo em Python
Instruções do exercicio
- Indique o tamanho da camada de saída da rede de políticas; para maior flexibilidade, use o nome da variável em vez do número real.
- Certifique-se de que a camada final retorne probabilidades.
exercicio interativo prático
Tente este exercicio completando este código de exemplo.
class PolicyNetwork(nn.Module):
def __init__(self, state_size, action_size):
super(PolicyNetwork, self).__init__()
self.fc1 = nn.Linear(state_size, 64)
self.fc2 = nn.Linear(64, 64)
# Give the desired size for the output layer
self.fc3 = nn.Linear(64, ____)
def forward(self, state):
x = torch.relu(self.fc1(torch.tensor(state)))
x = torch.relu(self.fc2(x))
# Obtain the action probabilities
action_probs = ____(self.fc3(x), dim=-1)
return action_probs
policy_network = PolicyNetwork(8, 4)
action_probs = policy_network(state)
print('Action probabilities:', action_probs)